xx点评简单后端项目
学后端到现在也算是开始写第一个可以称之为项目的东西了,虽然都在讲xx点评、xx外卖之类的项目没含金量,我也觉得简历里面写这种东西没什么竞争力,但花一两个星期写完我不认为不会有任何收获,看的也就是redis-黑马点评的那个视频
这个项目的前端页面已经提供了,我只需要完成后端接口即可。以各个功能模块的代码作为段落进行解析,记录一下写这个项目遇到的各种问题和学到的、弄明白的各种东西,所以不会贴完整的代码,完整代码会放到Github上,等写完了再传,欢迎品鉴shi山(
技术栈大概是springboot、mysql、redis、mybatisplus这些
准备工作
下载redis并导入到wsl里面,wsl就作为我的redis服务器了,挂着。视频提供了sql文件,创建一个数据库然后导入一下,相关命令为:
SOURCE hmdp.sql;配置文件里配置一下redis和mysql:
spring:
datasource:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/hmdp?useSSL=false&serverTimezone=UTC
username: xx
password: xx
redis:
host: 127.0.0.1
port: 6379
lettuce:
pool:
max-active: 10
max-idle: 10
min-idle: 1
time-between-eviction-runs: 10s还有前端环境一些杂七杂八的,挺简单的没学到什么东西,懒得写了。
短信验证码登录
需求分析和实现
第一个功能模块是做手机号-短信验证码登录的功能
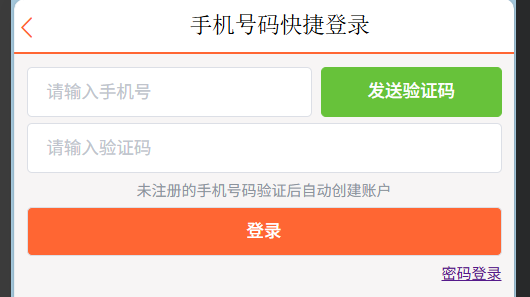
前端这里,当用户输入手机号并点击“发送验证码”的时候需要向后端请求验证码,验证码发送之后点击“登录”,又需要发送到后端进行验证
第一个请求是发送验证码,那么后端这里接收到的就是手机号,首先应该校验的就是手机号是否是正确的手机号,可以用正则来一个mismatch匹配:
public static final String PHONE_REGEX = "^1([38][0-9]|4[579]|5[0-3,5-9]|6[6]|7[0135678]|9[89])\\d{8}$";若手机号没问题,那么就可以随机生成一个验证码并发送给用户
第二个请求就是登录,后端需要校验用户的手机号和验证码是否匹配。若匹配成功,则又要判定用户是否存在,如果存在可以直接登录,否则应该先自动注册一个账号
那么这里牵扯到了一个矛盾。HTTP 协议本身是无状态的,服务器无法仅通过一次请求判断当前请求是否来自同一用户。为了在多次请求之间保存验证码等临时状态信息,可以使用 Session 机制
**Session 是由 Web 容器按照 Servlet 规范提供的一种会话管理机制,而tomcat是其中的一个实现方式。服务器会为每个客户端创建一个会话对象,并通过 Cookie(如 JSESSIONID)在客户端与服务器之间建立关联。**在发送验证码时,可以将手机号与验证码以键值对的形式存入 Session;在校验验证码时,再从 Session 中取出对应的值进行比对,从而完成验证
这么看来似乎可以解决现在的问题,但随着技术的发展,session机制渐渐暴露出来很多缺点。现代的后端服务器大多数是“集群式”,有很多的服务器来共同处理客户端发送的请求,客户端每次发送的请求可能都不是同一个服务器在处理,那么,因为session机制是服务器层面的技术,多服务器之间无法完成数据共享,虽然有一些解决办法,但都不太好用
那么就需要找一个好点的解决方法,这个方法就是Redis,一种键值对型的内存级数据库,可以提供集中式、高性能、可共享的状态存储。简单来说,它跟session不在一个状态层面,独立于web容器存在,因此各个服务器都可以访问同一个redis,这样就解决了数据共享的问题。
在第一个请求中,生成验证码之后需要把它存到redis数据库里面,Java提供了api,相关代码如下:
stringRedisTemplate.opsForValue().set(LOGIN_CODE_KEY+phone,code,LOGIN_CODE_TTL, TimeUnit.MINUTES);String code = stringRedisTemplate.opsForValue().get(LOGIN_CODE_KEY+phone);解决了这个问题,再回到刚刚的登录需求
前面提到过HTTP请求是无状态的,那么登录完成之后客户端要知道自己已经登录了,仍然可以用redis来存储登录状态。具体实现方案为: 使用redis的string-hash结构来存储,key段存储一串token(可以用随机生成的UUID),value段存储用户信息,然后把token返回给前端,以后客户端每次请求都携带这个token,服务端再进行校验即可。
但是,原来的用户类User保存了太多的信息,如果直接把它转成Map然后存到redis里面,再返回给前端的话,HTTP请求体里面会直接暴露用户的敏感信息,那么则需要一个“中间类”,只做必要的校验,舍弃掉敏感信息即可,同时应该注意设置有效期,防止用户数量过多把redis存储空间占满
到此为止短信验证码登录就完成了
拦截器
前面提到,服务端需要校验从客户端发来的token以鉴别用户,那么我们不可能在每个service方法里面都写个校验,应该把它总结到一个地方,也就是spring MVC提供的拦截器(注意区分它与过滤器)
一次HTTP请求的执行顺序如下:
客户端请求
↓
Filter(编码 / 跨域等)
↓
DispatcherServlet
↓
Interceptor.preHandle()
↓
Controller
↓
Interceptor.postHandle()
↓
Interceptor.afterCompletion()首先创建一个类LoginInterceptor,它需要继承接口HandlerInterceptor,然后根据业务需求,需要实现里面的方法preHandle,在这里面做登录校验即可,首先获取token
String token = request.getHeader("Authorization");然后用这个token去数据库里面找用户,如果token或用户不存在直接返回401即可,如果存在则先把它转成UserDTO对象,然后把它存到…
存到哪?我要在后面的controller、service继续使用这个用户,可是我应该把它存在什么地方?
第一个想法是,我的redis里面都有这个用户了,直接照着token拿不就完了。但是,这里的token是前端传来的,要从HTTP请求体里面拿,也就是说:
-
Controller 传一次
-
Service 再传
-
每层都要带 token
那么参数会爆炸,而且后续的业务逻辑里面还要写查询,会导致重复的IO,性能很差且污染业务逻辑
把它塞到HTTP请求体里面,然后让后面的controller自己get一下?也一样会污染参数和业务逻辑。
这里可以用ThreadLocal,它的作用很简单:同一个线程里,随便在哪,都能拿到这份数据;换一个线程,互相看不见,真实的数据在堆内存中,它只存引用
核心原理是,一次HTTP请求就认为是一个线程,那么需要的机制也就是在一次请求内,全局可用,但又不会串请求,这就是ThreadLocal干的
// 将Hash数据转为UserDTO对象
UserDTO userDTO = BeanUtil.fillBeanWithMap(userMap,new UserDTO(),false);
UserHolder.saveUser(userDTO);这里如果不写saveUser的操作,当请求走出拦截器代码部分时,userDTO对象就会被销毁。写了之后则会提升它的作用域,使它一直存在于堆内存中,后续可以用ThreadLocal获取,不用传任何参数,本质是把这个userDTO变成了逻辑上的全局变量,物理上的线程私有变量
唯一需要注意的是,一定要在controller结束后UserHolder.removeUser()删掉这次的对象,否则线程池复用可能把上一个请求的数据“泄露”到下一个请求,造成严重的安全问题。
到这里为止,短信验证码登录和校验功能都已经完成了,但这里有一个细节性的东西还是可以修改一下。
之前写的拦截器代码里面做了登录状态(即token)的刷新,但这个拦截器并不是拦截一切路径,它只拦截一些做登录校验的路径。可是如果用户一直在访问比如首页、商户详情页之类不需要登录的页面,一定时间之后他的登录状态会被取消,显然不太合理
改进方法就是再加一个拦截器,把这两个拦截器的功能隔开,一个做token刷新,一个负责拦截即可,代码也不用动太多,稍微改改就行
商户查询缓存
需求分析
由于redis的读写速度极快,因此可以用作客户端-服务端-数据库之间的缓存区域,具体模型如下:
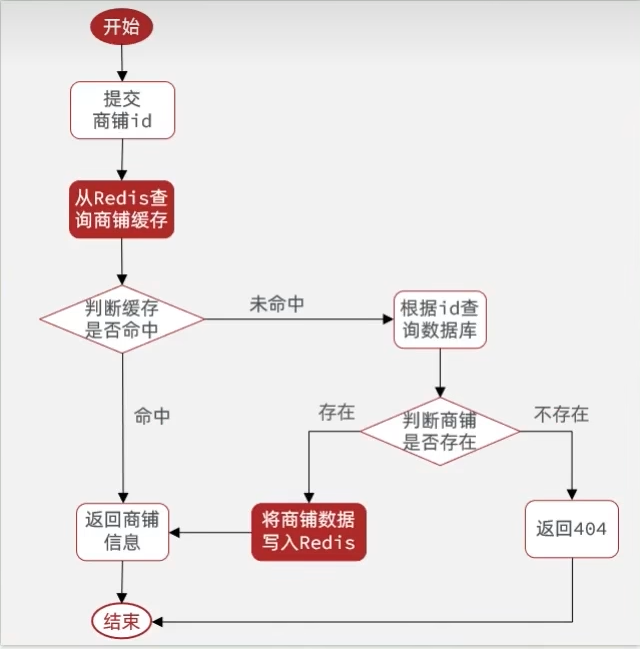
简单写段代码,然后在前端刷新页面,可以发现第一次查询和第二次查询的请求时间明显降低,从秒级到了毫秒级
这里踩了个坑
MyBatis-Plus 的
list()不会返回 null,只会返回:
- 空 List
- 或非空 List
也就是说不能用list == null来判空,得用list.isEmpty(),用null来判断会导致代码变为“死代码”,永远不会进这个逻辑
缓存更新策略
如果数据库的数据更新了但缓存的数据还是老数据,就会导致客户端查询到的数据与数据库的数据出现差异,因此需要及时更新缓存中的数据,常见的缓存更新思路包括先删除缓存再更新数据库、先更新数据库再删除缓存等方式。在并发读写场景下,由于数据库操作与缓存操作之间不存在原子性,可能会出现短暂的数据不一致问题,导致客户端拿到的数据有误
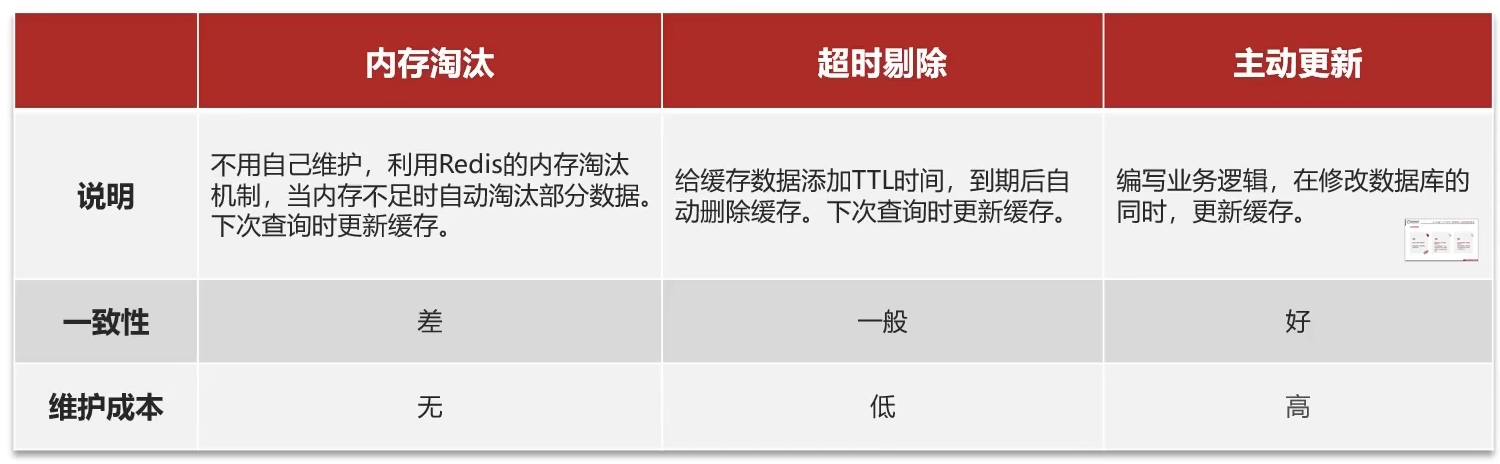

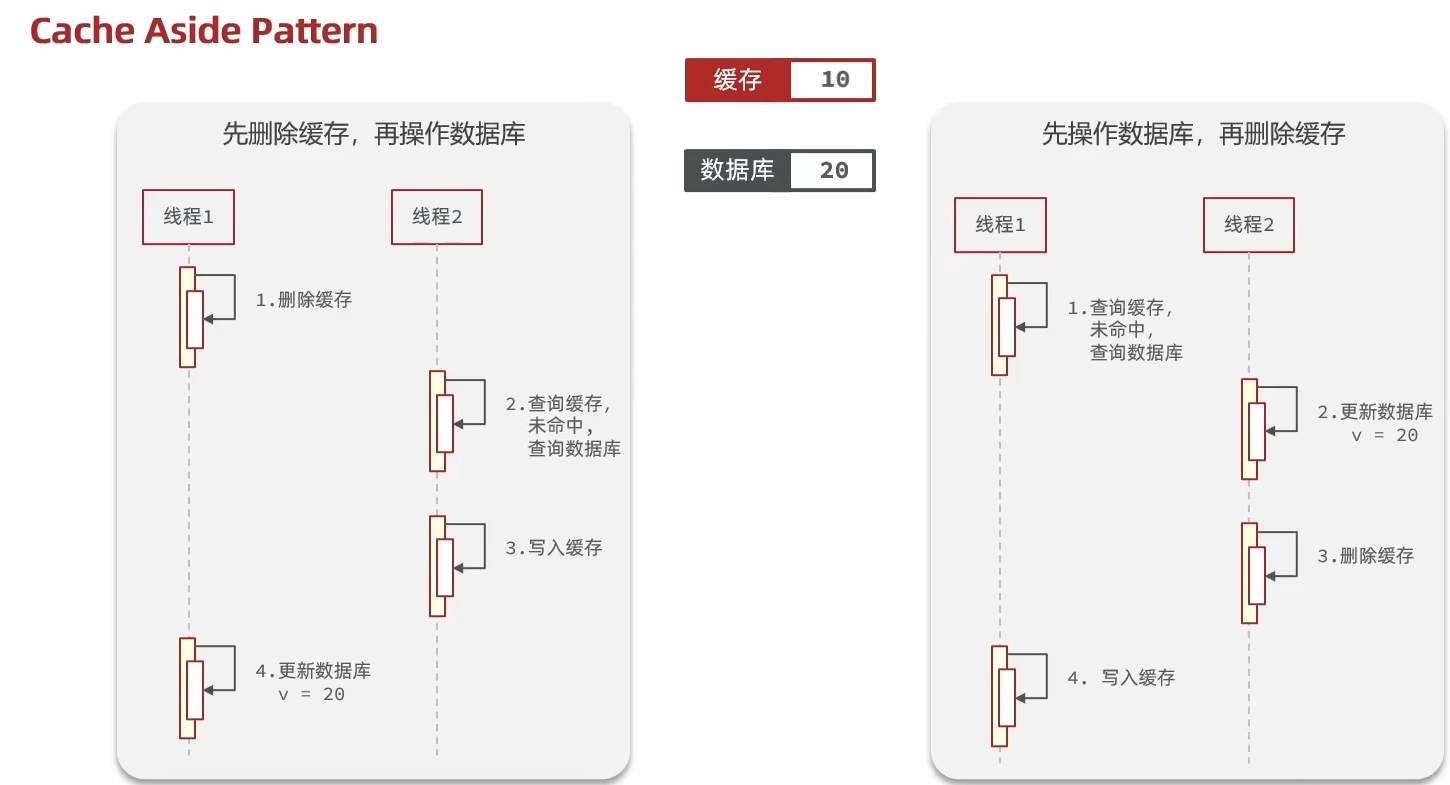
大致思路如上,缓存一致性问题主要来源于并发时序问题(读写竞争)和分布式环境下的操作非原子性,像现在写的单体系统不用在意太多,先了解一下即可。尤其注意一下第三张图的并发问题,相对于缓存操作来说,数据库操作速度极慢。因此先更新数据库再删除缓存,虽然仍存在并发读写导致短暂不一致的可能,但在实际应用中出现概率较低,且可通过缓存过期时间进行最终一致性兜底,故在项目中常用第二种方案
缓存穿透
缓存穿透指的是客户端请求的数据在缓存和数据库中都不存在,这样缓存永远不会生效,但每次的请求都会发送到数据库。如果有人利用这个漏洞向服务器发送大量无意义的请求数据,很有可能会导致服务器过载以至于崩溃,因此有必要解决这种问题
解决方法有两种:
-
缓存空对象
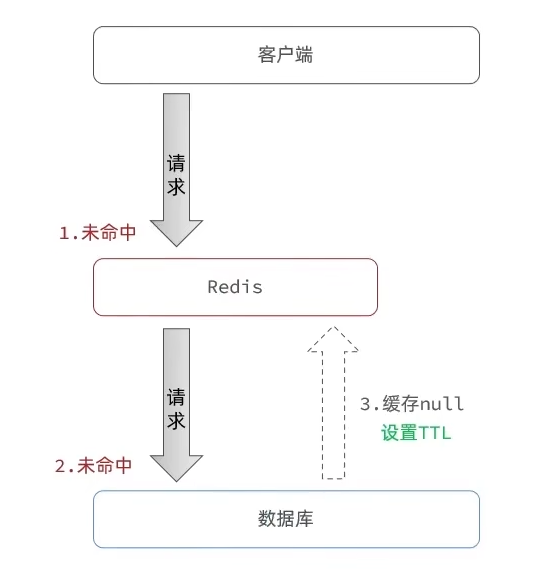
-
具体实现方法为:如果用户发送的请求在缓存和数据库中都不存在,那么也会缓存一个null数据到缓存中
-
优点是实现简单,维护方便,可操作性比较大
-
缺点是会导致额外的内存消耗及可能会导致短期的数据不一致
-
-
布隆过滤
这个东西暂时不用深入了解原理,大致知道它是用哈希算法进行的,不用真正存储数据库所有数据的一种方法即可
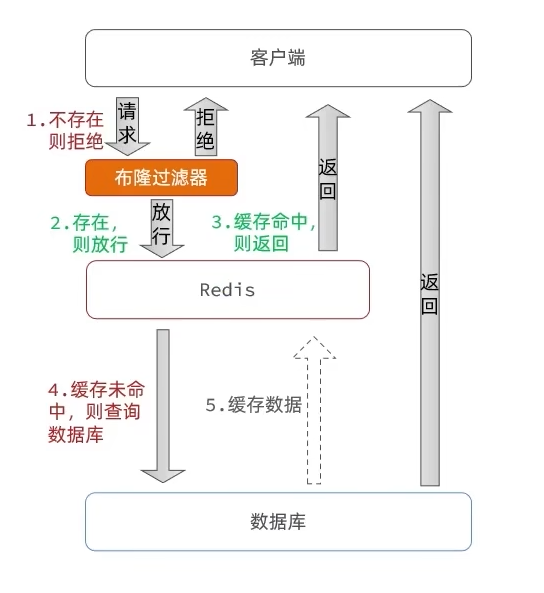
- 优点是占用内存较少,不用存储多余的key
- 缺点是实现复杂且有误判可能(若被布隆过滤器识别为存在不一定是真的存在,这样的话仍可能出现穿透现象)
上面两个方法是较为常见的被动防御缓存穿透,但实际上还有一些主动防御的方法,比如对请求进行校验,不符合要求的直接拦截等方法。这里先不深入了
知道了缓存穿透这个现象,那就应该修改一下前面的缓存代码,采用的是第一种方法,相关代码为:
// 防御缓存穿透相关代码,留作备份
// public Shop queryWithPassThrough(Long id){
// String key = CACHE_SHOP_KEY + id;
// // 从redis查询缓存
// String shopJson = stringRedisTemplate.opsForValue().get(key);
//
// // 注意这里的isNotBlank仅仅判断查询到的shopJson有没有值,null、空值等不包括在内,因此下面还要做一次校验
// if (StrUtil.isNotBlank(shopJson)){
// return JSONUtil.toBean(shopJson, Shop.class);
// }
//
// // 如果查询到的不是null,那么就只能是我们设置的空值
// if (shopJson != null) {
// return null;
// }
//
// Shop shop = getById(id);
// // 如果数据库里面都不存在,则需要先缓存一下空值,然后返回fail
// if (shop == null){
// stringRedisTemplate.opsForValue().set(key,"",CACHE_NULL_TTL + RandomUtil.randomLong(1,6),TimeUnit.MINUTES);
// return null;
// }
// // 若存在则先保存到redis,然后返回给用户
// stringRedisTemplate.opsForValue().set(key,JSONUtil.toJsonStr(shop),CACHE_SHOP_TTL + RandomUtil.randomLong(1,6), TimeUnit.MINUTES);
//
// return shop;
// }缓存雪崩
缓存雪崩指的是同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求直接打入数据库带来巨大访问压力
解决方法有下面这些:
- 给不同Key的TTL添加几分钟的随机值
- 利用Redis集群提高服务的可用性(微服务集群方面)
- 给缓存业务添加降级限流
- 给业务添加多级缓存(浏览器端、JVM端等)
代码方面采用的是简单的第一种
缓存击穿
也称为热点key问题,指的是一个被高并发访问且缓存业务重建较为复杂的key突然失效了,大量访问请求会瞬间冲向数据库以过载。
缓存业务重建较为复杂指的是某些数据不仅仅是查一个数据库而得,可能需要多表查询甚至进行大量计算才可以得到,缓存重建的时间比较久的一种情况。此时它又是一个热点key,有大量并发线程来访问,那么就会出现这种情况:
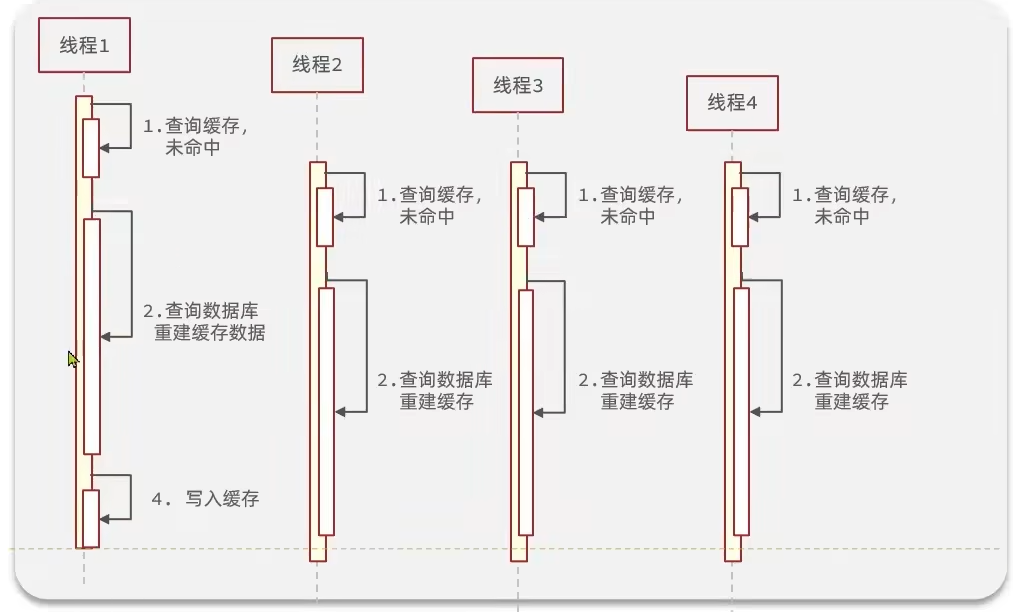
在重建缓存过程中,大量线程都会未命中缓存,导致大量线程同时查询数据库并进行缓存重建,这一超高爆发对数据库会带来极大冲击
解决方法有两个:互斥锁和逻辑过期
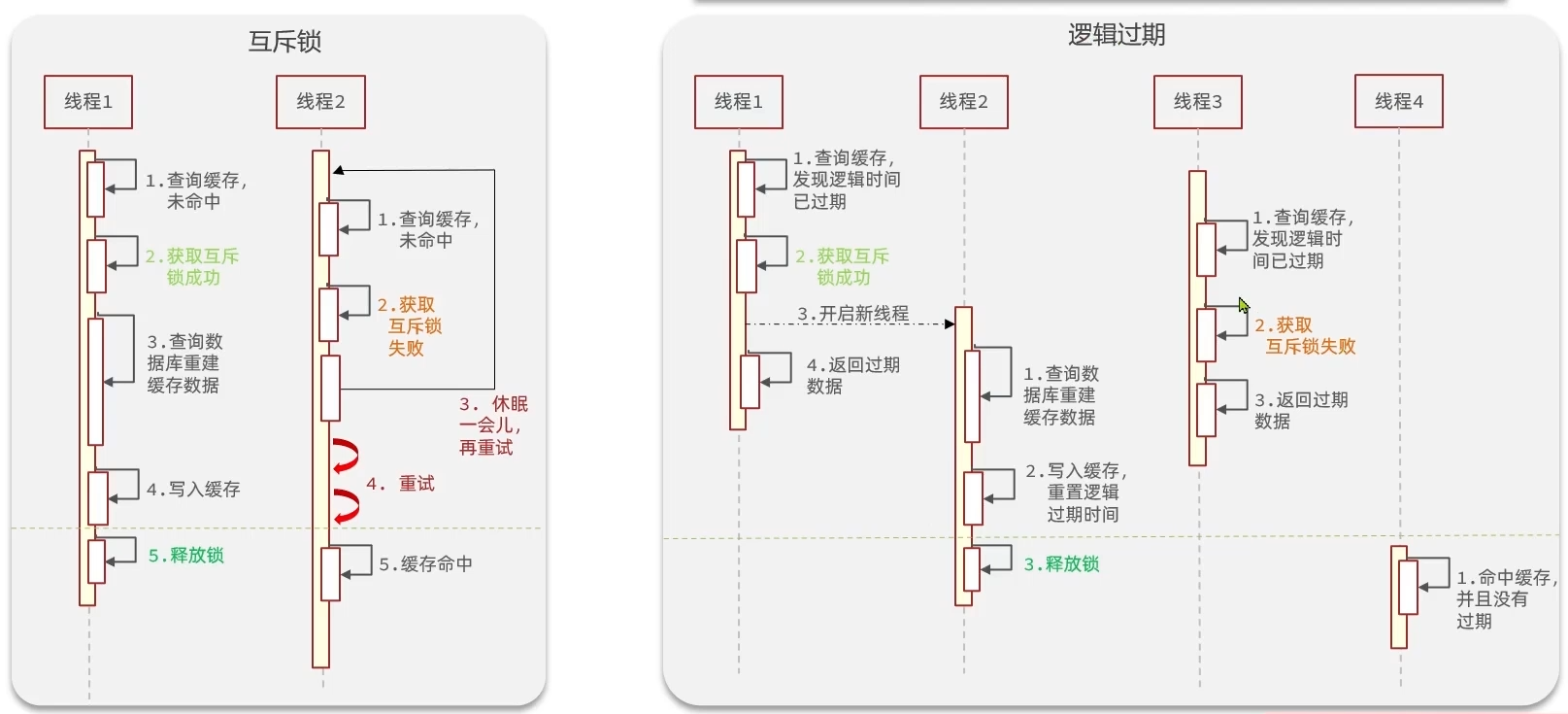
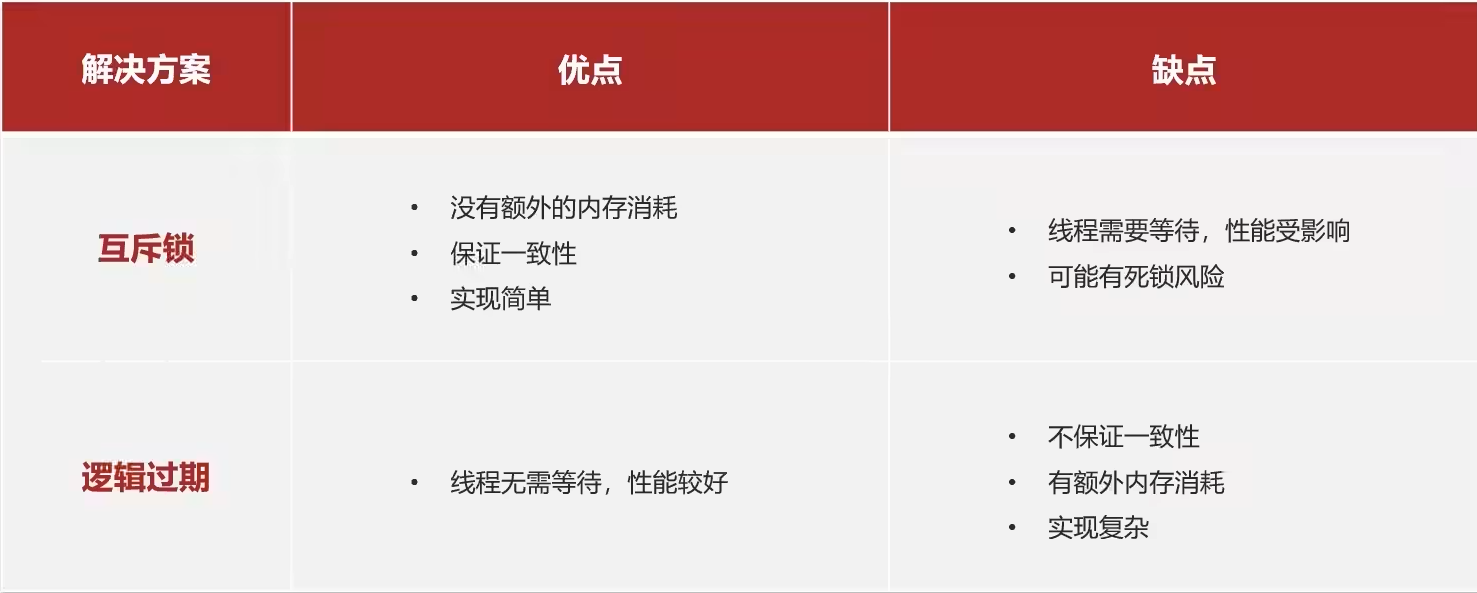
要解决的问题只有一个:防止多个线程一块去查询数据库导致数据库访问量过多而崩溃。只能让一个线程去查数据库
这边我的代码里面两种方法都写了,留作一个备份
互斥锁
这里没有用Java提供的lock机制,而是通过redis的setnx关键字来实现简单自定义互斥锁,具体操作看代码即可,大致思路为
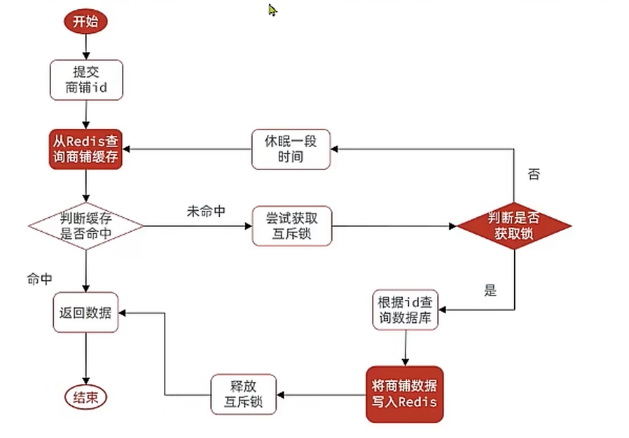
一开始写的原始代码长这样:
public Shop queryWithMutex(Long id){
String key = CACHE_SHOP_KEY + id;
// 从redis查询缓存
String shopJson = stringRedisTemplate.opsForValue().get(key);
// 注意这里的isNotBlank仅仅判断查询到的shopJson有没有值,null、空值等不包括在内,因此下面还要做一次校验
if (StrUtil.isNotBlank(shopJson)){
return JSONUtil.toBean(shopJson, Shop.class);
}
// 如果查询到的不是null,那么就只能是我们设置的空值
if (shopJson != null) {
return null;
}
// 到这为止就是“未命中”,需要尝试获取互斥锁
String keyLock = LOCK_SHOP_KEY + id;
Shop shop = null;
try {
// 如果锁获取失败,那么需要休眠一段时间再来获取,用递归实现
if (!tryLock(keyLock)) {
Thread.sleep(50);
return queryWithMutex(id);
}
shop = getById(id);
// 如果数据库里面都不存在,则需要先缓存一下空值,然后返回fail
if (shop == null){
stringRedisTemplate.opsForValue().set(key,"",CACHE_NULL_TTL + RandomUtil.randomLong(1,6),TimeUnit.MINUTES);
return null;
}
// 若存在则先保存到redis,然后返回给用户
stringRedisTemplate.opsForValue().set(key,JSONUtil.toJsonStr(shop),CACHE_SHOP_TTL + RandomUtil.randomLong(1,6), TimeUnit.MINUTES);
} catch (Exception e) {
throw new RuntimeException(e);
}finally {
unlock(keyLock);
}
return shop;
}有几个点需要注意,也就是我代码的修改处
在try-catch-finally里面有这样一句:return queryWithMutex(id),执行顺序是先queryWithMutex(id)->保存返回值->finally->返回返回值。
那么中间有这样一段逻辑:
public Shop queryWithMutex(Long id) {
boolean isLock = tryLock();
try {
if (!tryLock(keyLock)) {
Thread.sleep(50);
return queryWithMutex(id);
}
} finally {
unlock(keyLock);
}
}模拟一下: 一个线程来了尝试获取锁,如果没有拿到则进入if语句进行递归->第二次递归假设拿到了锁
那么在第二次递归中,由于它拿到了锁,那么就不会进if语句,继续下面的查询数据库->添加缓存->走到finally里面释放锁->返回结果到上一层递归,然后由上一层递归再返回出去。
似乎没问题?但实际上当上一层(也就是第一层)递归在返回之前,它也要进一次finally并进行unlock释放锁,如果说在释放锁之前有另一个线程刚好拿到锁,由于我的代码中锁的key是一致的String keyLock = LOCK_SHOP_KEY + id,那么此时就会把另一个线程的锁释放掉
改进了之后出现的第二个问题是,我加的锁是有TTL的,那么就不可避免地会出现锁过期的现象,可以预料到这样的场景:
A线程还没有执行完,他的锁就过期了。此时有一个线程B拿到了锁,如果刚好A线程进了finally段,此时它的isLock校验是可以过的,那么就把线程B的锁释放掉了。
解决问题也很简单,既然可能会导致误删,那么我给每个线程拿到的锁都做一个特定标识,在释放锁的时候都去校验一下这个标识不就好了?标识可以对value进行操作,因为前面的代码里面这个值都是固定的“1”,正好可以用来做唯一性标识
思路没问题,改一下代码即可,释放锁那里的代码一开始可能会想着改成这样:
String valueInRedis = stringRedisTemplate.opsForValue().get(key);
if (lockValue.equals(valueInRedis)) {
stringRedisTemplate.delete(key);
}既然我要根据value来判断,那我直接取出来比一下就行了
在以往的代码中,这种思路没什么问题,因为写的都是单线程。可是在多线程模式下这个思路会出现很大的安全隐患
中间可能发生并发:
- 线程 A
get得到 value"v1",然后经过了校验 - 线程 A 还没
delete - 线程 B 抢到了锁,把 key 设置成
"v2" - 线程 A 执行
delete→ 删掉了 B 的锁
那么这里就应该引入一个新的概念,用Redis 支持的 内嵌 Lua 脚本,可以把多条命令包装成单条原子操作
Lua 是一种轻量级脚本语言:
- 语法简单、像 Python / JavaScript 一样动态
- 内存占用小,执行效率高
- 适合嵌入到其他程序里当“脚本引擎”使用
没学过这东西,代码里的Lua是ai写的,这里贴一下各个段落的作用:
if redis.call('get', KEYS[1]) == ARGV[1] then
return redis.call('del', KEYS[1])
else
return 0
end
/*
KEYS[1] → Redis 脚本的第一个 key,在 Java 里传的是锁 key
ARGV[1] → Redis 脚本的第一个参数,在 Java 里传的是锁 value(UUID token)
redis.call('get', KEYS[1]) → 拿到当前锁的 value
判断 get(key) 是否等于我们自己的 token(保证安全解锁)
相等 → 删除锁 (del) 并返回 1
不相等 → 不删除,返回 0
*/stringRedisTemplate.execute(
UNLOCK_SCRIPT, // Lua 脚本
Collections.singletonList(key),// KEYS
value // ARGV
);| 参数 | 含义 |
|---|---|
UNLOCK_SCRIPT | 要执行的 Lua 脚本封装对象,包含脚本内容和返回类型 |
Collections.singletonList(key) | Lua 脚本的 KEYS 数组,在 Lua 里通过 KEYS[1] 获取 |
value | Lua 脚本的 ARGV 数组,在 Lua 里通过 ARGV[1] 获取 |
跑了个测试类,只有第一个线程去查了数据库,其它的49个都走的缓存,目的应该是达到了
毕竟本地的数据库访问速度挺快的,也懒得再去模拟其他情况了。没看出来啥问题,就到这里吧
@Test
public void testConcurrentQuery() throws InterruptedException {
Long id = 1L;
stringRedisTemplate.delete(CACHE_SHOP_KEY + id); // 模拟缓存未命中
// 模拟50个并发请求
int threadCount = 50;
CountDownLatch latch = new CountDownLatch(threadCount);
// 循环启动50个线程,第一个线程拿到锁去查询数据库,然后存到缓存里面,其它的线程阻塞等待第一个线程拿到数据或者超时返回null
for (int i = 0; i < threadCount; i++) {
new Thread(() -> {
try {
Shop shop = (Shop) shopService.queryById(id).getData();
System.out.println(Thread.currentThread().getName() + ": " + shop);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
latch.countDown();
}
}).start();
}
latch.await();
}逻辑过期
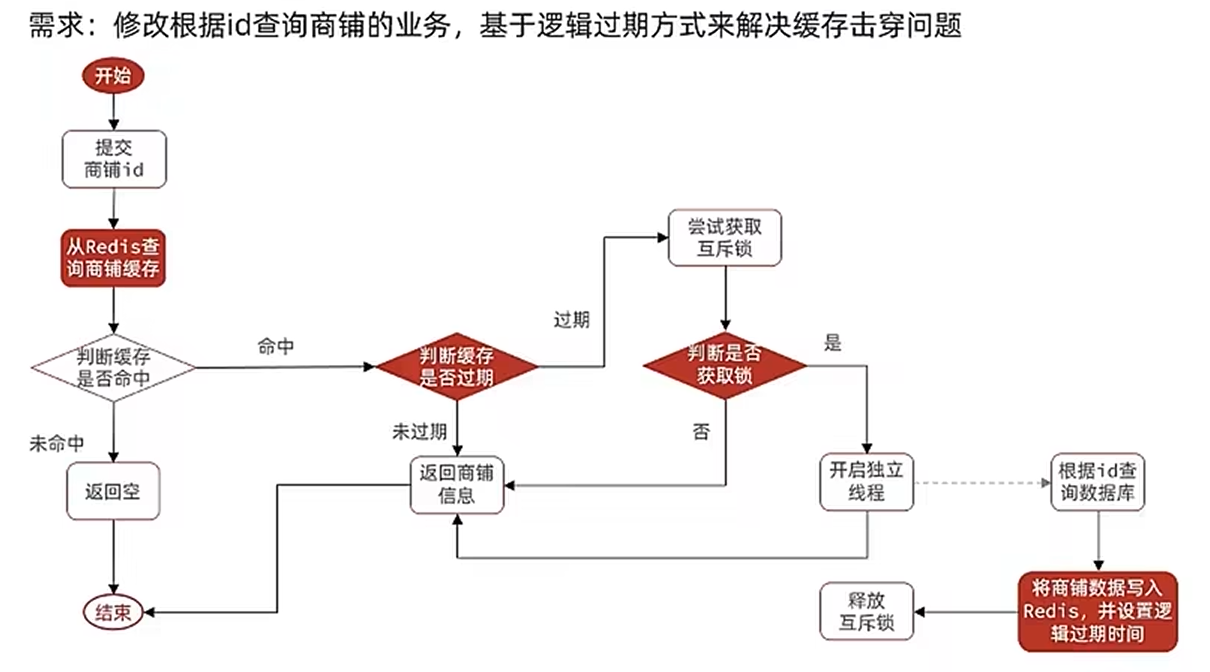
这里默认一定命中,若未命中则认为不是热点key,不需要处理
对于我的代码:
// 创建10个线程池
private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10);
// 逻辑过期解决缓存穿透
public Shop queryWithLogicalExpire(Long id){
String key = CACHE_SHOP_KEY + id;
// 从redis查询缓存
String shopJson = stringRedisTemplate.opsForValue().get(key);
// 这里默认一定命中,若未命中则认为不是热点key,不需要处理
if (StrUtil.isBlank(shopJson)){
return null;
}
// 若命中则需要判断缓存是否过期,先把查询到的redis字符串反序列化为对象
RedisData redisData = JSONUtil.toBean(shopJson,RedisData.class);
Shop shop = JSONUtil.toBean((JSONObject) redisData.getData(),Shop.class);
LocalDateTime expireTime = redisData.getExpireTime();
// 判断逻辑是否过期,若未过期则直接返回即可,如果过期,则需要利用互斥锁,让一个线程去重建缓存,其它的线程先直接返回过期信息即可
if (expireTime.isAfter(LocalDateTime.now())){
return shop;
}
String keyLock = LOCK_SHOP_KEY + id;
String valueLock = UUID.randomUUID().toString();
boolean isLock = tryLock(keyLock,valueLock);
// 拿到锁了之后新创建一个新的线程,让它去重建缓存,自己先直接返回旧数据
if (isLock){
// 拿到锁之后仍然要做一次double check
shopJson = stringRedisTemplate.opsForValue().get(key);
if (StrUtil.isNotBlank(shopJson)) {
redisData = JSONUtil.toBean(shopJson,RedisData.class);
if (redisData.getExpireTime().isAfter(LocalDateTime.now())){
shop = JSONUtil.toBean((JSONObject) redisData.getData(),Shop.class);
unlock(keyLock,valueLock);
return shop;
}
}
CACHE_REBUILD_EXECUTOR.submit(() -> {
try {
this.saveShop2Redis(id,20L);
} catch (Exception e){
// 异步线程抛异常不会回到主线程,因此其抛异常没有什么意义,应该做一下日志
log.error("缓存重建失败,shopId={}", id, e);
}finally{
unlock(keyLock,valueLock);
}
});
}
return shop;
}有一些点提一下,做个笔记。
这里的线程池是懒创建的,当第一次出现submit,发生的事情是:
- 线程池发现:当前线程数 < 10
- 创建一个新线程
- 用这个线程执行你的任务
第二次 submit,如果第一个线程还在忙,那就再创建一个新线程
直到最多创建 10 个线程时,再多任务 → 排队
也就是说它们不会一开始就创建10个。
submit那里用的lambda表达式,原语法应该为
new Runnable() {
@Override
public void run() {
this.saveShop2Redis(id, 20L);
}
}写到这里突然发现一件事,就是前面的几个问题都有多种解决方案,我想都留存下来作为学习用,但是都写在项目文件里面然后用注释来保存感觉也太丑了。。。而且真实项目肯定也不会这么干。同时,Service层不应该做这么多东西,把很多方法都写在里面显得很臃肿
联想到之前学的一些配置类,应该可以把自己写的各种方法也作为一种“策略”,然后提供接口,再用类似配置类的形式规定接口使用哪个实现,这样既方便后续更改,也不会把项目代码搞得太丑,还保证了Service层的功能性
方案有了,那么就来实现(大量借助ai。。。。 code水平真的有待提升)
首先创建了一个ShopCacheStrategy接口,用于Service层的调用,然后创建两个类作为实现类,分别实现对应的query方法。
同时我新建了一个工具类包,用于存放一些工具类,我把取与释放锁的相应代码写到了里面,保证一下Service的简洁。
一开始我没有动太多,就是直接把代码挪到不同地方而已。但这样做会导致实现类里面仍然需要调用getById方法,也就是说我还需要让策略实现类继承那个mp父类,这显然有点“越权”嫌疑。
那么,如果我的这些类里面不能出现getById,那应该怎么查询数据库?其实这里面根本就不应该查询数据库,因为它只是一个解决问题的实现类,不应该让它与数据库产生交互
但是我重建缓存的时候又得进行double check,不查数据库怎么看?
可以用Supplier
Supplier<T> 是 Java 8 的一个 函数式接口,定义在 java.util.function 包里:
@FunctionalInterface
public interface Supplier<T> {
T get();
}它很简单:就是一个没有参数,但会返回一个值的“工厂/提供者”。
- 调用
get()方法,返回一个T类型的对象。 - 它没有参数,只有返回值。
也就是说,我可以用它的get方法获取一个类型为T的对象。那么这个对象怎么来?从数据库里面查。在哪查?不能在实现类里面查,应该在Service里面查
所以我在Service层里面写的是:
Shop shop = cacheStrategy.queryById(id, () -> getById(id));第二个参数为lambda表达式,()表示没有参数,getById(id)表示supplier的返回值。
当调用dbFallback.get()时,代码才会走这个getById来获得shop对象并返回,而这一过程是在调用处的类进行的,而不是在实现类处进行的
这里还有另一种方式。用Function<R,T>,功能上没什么区别,也没有说哪个更好,只是适用范围不同:
-
Supplier的泛型只作为返回值类型,参数通过闭包捕获,接口本身无参数
-
而Function的两个泛型分别是参数类型和返回值类型,含义是“给我一个 R,我返回一个 T”,参数通过
apply显式传入,当调用apply方法的时候传入参数
方案切换的话,因为方案比较少,所以我简单写了个Config类,用原生的Spring方案结合yaml配置文件来更改配置,这样更换实现类的时候只用改一下配置文件即可
shop:
cache:
strategy: mutexStrategy总结
这一节的主要需求就是缓存问题。因为查询数据库所用的时间过长,所以我们需要把会被多次查询到的数据存到一个缓存空间(类似于电脑的“内存”)以提高服务性能,也可以保证服务器的稳定性。而在做缓存需求的时候又会出现很多问题,比如:
- 缓存的数据可能与数据库的数据不一致,此时要更新缓存,更新缓存的话又会出现等等问题
- 缓存拿不到就去找数据库,万一数据库也没有,此时缓存就形同虚设
- 缓存的空间远小于数据库,哪些数据应该存到缓存,哪些不应该
- 多线程下的大量并发可能会导致哪些没有被考虑到的问题?
基于解决需求时遇到的问题,又出现了种种解决方案,于是在解决缓存问题的基础上又引申学习了很多策略来解决遇到的问题
优惠券秒杀
全局唯一ID及实现
联系实际可以明白,订单数据的id不能直接用mysql数据库的自增解决:
- id规律太明显
- 受表的数据量限制
因此要生成“全局ID”,保证全局内的id都一致,且id必须无规律
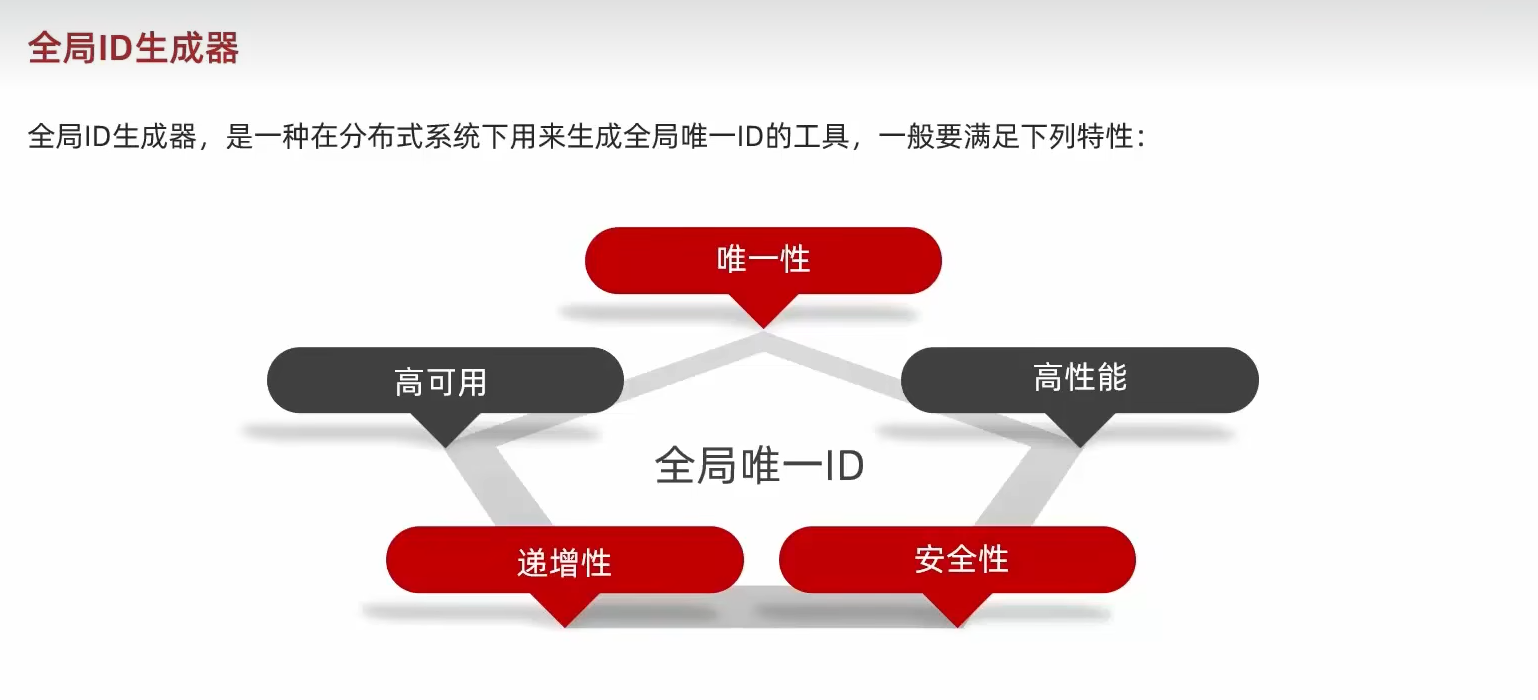


这里利用的是redis的字符串自增策略来解决的问题,序列号为:符号占位符+时间戳+实际序列号(共64bit),代码比较短就贴在这了:
package com.hmdp.utils;
/*
全局id生成工具类
生成的id共为64bit的序列号,第一位为符号位(不用管),中间31位为时间戳,后面32位为实际递增的序列号
*/
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import java.time.LocalDateTime;
import java.time.ZoneOffset;
import java.time.format.DateTimeFormatter;
@Component
public class RedisIdWorker {
@Resource
private StringRedisTemplate stringRedisTemplate;
// 初始时间戳
private static final long BEGIN_TIMESTAMP = 1640995200L;
// 时间戳左移的位数,可更改
private static final int COUNT_BITS = 32;
public long nextId(String keyPrefix){
// 生成时间戳
LocalDateTime now = LocalDateTime.now();
long nowSecond = now.toEpochSecond(ZoneOffset.UTC);
long timestamp = nowSecond - BEGIN_TIMESTAMP;
/*
用redis的字符串自增策略生成序列号
*/
String date = now.format(DateTimeFormatter.ofPattern("yyyy:MM:dd"));
// 把key对应的value + 1,若不存在则视为0(value必须不存在或者为整数,非整数均会报错)
long count = stringRedisTemplate.opsForValue().increment("icr:" + keyPrefix + ":" + date);
return timestamp << COUNT_BITS | count;
}
}测试方法为:
@Autowired
private RedisIdWorker redisIdWorker;
// 创建一个 最多 500 个线程的线程池
private static final ExecutorService es = Executors.newFixedThreadPool(500);
@Test
public void testRedisIdWorker() throws InterruptedException {
// 可以理解为一个300的计数器。每完成一个任务-1,变成 0 时await() 才会放行
CountDownLatch latch = new CountDownLatch(300);
// 每个用户请求 100 次 ID,共300个线程,所以一共发起了300x100=30000个请求
Runnable task = () -> {
for (int i = 0; i < 100; i++){
long id = redisIdWorker.nextId("order");
System.out.println("id = " + id);
}
// 表示一个进程结束了
latch.countDown();
};
long begin = System.currentTimeMillis();
for (int i = 0; i < 300; i++) {
es.submit(task);
}
// 阻塞当前测试线程,直到 300 个 task 全部执行完
latch.await();
long end = System.currentTimeMillis();
System.out.println("time = " + (end - begin));
}添加秒杀优惠券
先看看秒杀优惠券的实体类,有些注解不太懂,写了些注释
package com.hmdp.entity;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
import lombok.EqualsAndHashCode;
import lombok.experimental.Accessors;
import java.io.Serializable;
import java.time.LocalDateTime;
/**
* <p>
* 秒杀优惠券表,与优惠券是一对一关系
* </p>
*
* @author 虎哥
* @since 2022-01-04
*/
@Data
@EqualsAndHashCode(callSuper = false)
@Accessors(chain = true)
// 上面三个注解均是lombok
// EqualsAndHashCode表示生成 equals 和 hashCode 时,不调用父类的字段
// 意思就是在判断两个对象是否相等、以及计算哈希值时,只看当前这个类自己声明的字段,不管它父类里有什么字段,但这个类没父类,所以可有可无
// Accessors表示开启链式调用
@TableName("tb_seckill_voucher")
// 告诉 MyBatis-Plus这个实体类对应哪张表。如果没有它,MyBatis-Plus 会默认SeckillVoucher → seckill_voucher
// Serializable表明这个对象可以被序列化(变成字节流)
public class SeckillVoucher implements Serializable {
// 防止序列化版本不一致导致反序列化失败,一般写1L,不写也可以
private static final long serialVersionUID = 1L;
/**
* 关联的优惠券的id
*/
// value表示Java 字段 voucherId ↔ 数据库字段 voucher_id。
// type表示MyBatis-Plus 主键策略,这里用的是INPUT,表明插入 tb_seckill_voucher 时,voucher_id 必须自己传
@TableId(value = "voucher_id", type = IdType.INPUT)
private Long voucherId;
/**
* 库存
*/
private Integer stock;
/**
* 创建时间
*/
private LocalDateTime createTime;
/**
* 生效时间
*/
private LocalDateTime beginTime;
/**
* 失效时间
*/
private LocalDateTime endTime;
/**
* 更新时间
*/
private LocalDateTime updateTime;
}理解了之后,先测试一下现有的添加秒杀券功能addSeckillVoucher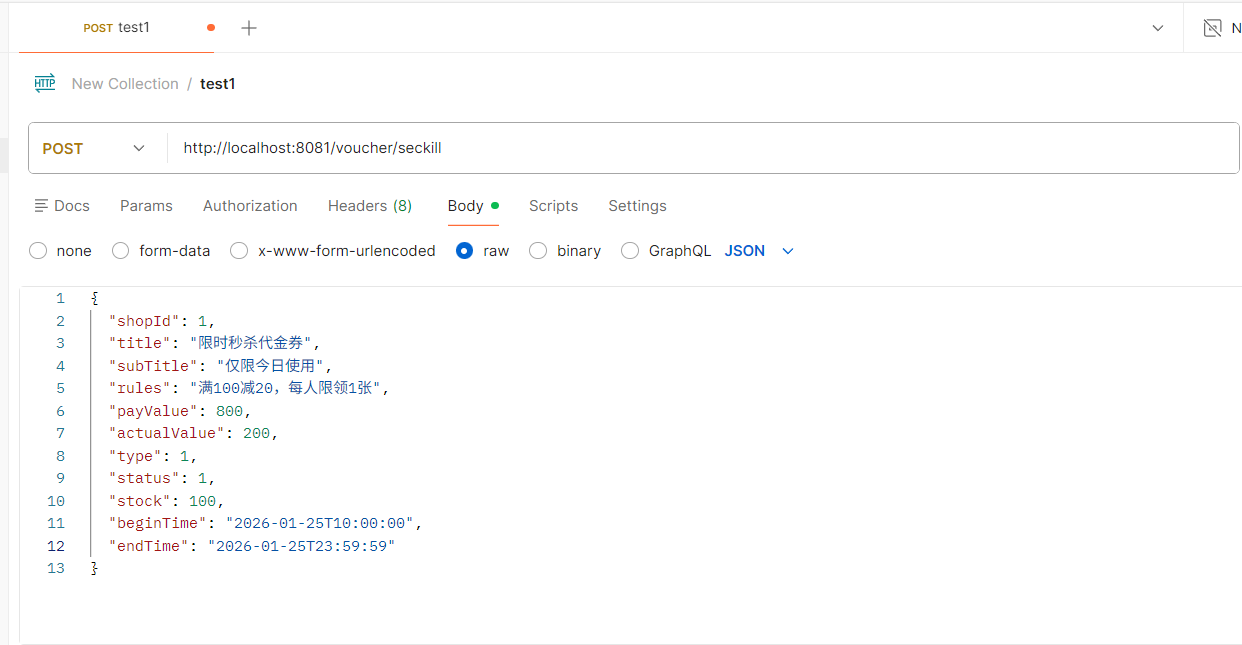
由于MvcConfig那里放行过了,因此这里不需要登录也能正常发出请求
优惠券秒杀下单功能
一开始完成的下单代码逻辑如下:
package com.hmdp.service.impl;
import com.hmdp.dto.Result;
import com.hmdp.entity.SeckillVoucher;
import com.hmdp.entity.VoucherOrder;
import com.hmdp.mapper.VoucherOrderMapper;
import com.hmdp.service.ISeckillVoucherService;
import com.hmdp.service.IVoucherOrderService;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.hmdp.utils.RedisIdWorker;
import com.hmdp.utils.UserHolder;
import org.apache.tomcat.jni.Local;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import java.time.LocalDateTime;
/**
* <p>
* 服务实现类
* </p>
*
* @author 虎哥
* @since 2021-12-22
*/
@Service
public class VoucherOrderServiceImpl extends ServiceImpl<VoucherOrderMapper, VoucherOrder> implements IVoucherOrderService {
@Resource
private ISeckillVoucherService seckillVoucherService;
@Resource
private RedisIdWorker redisIdWorker;
@Override
public Result seckillVoucher(Long voucherId) {
// 查询优惠券
SeckillVoucher voucher = seckillVoucherService.getById(voucherId);
// 判断秒杀时间
if (voucher.getBeginTime().isAfter(LocalDateTime.now()) || voucher.getEndTime().isBefore(LocalDateTime.now())){
return Result.fail("当前不在秒杀时间");
}
// 判断库存数量
if (voucher.getStock() < 1){
return Result.fail("库存不足");
}
// 先让库存数减一
boolean success = seckillVoucherService.update()
.setSql("stock = stock - 1")
.eq("voucher_id", voucherId).update();
if (!success){
// 扣减库存失败,一般认为也是库存不足
return Result.fail("库存不足");
}
// 创建订单
VoucherOrder voucherOrder = new VoucherOrder();
// 获取订单id,用前面的全局id生成器
long orderId = redisIdWorker.nextId("order");
voucherOrder.setId(orderId);
// 获取用户id,用UserHolder
Long userId = UserHolder.getUser().getId();
voucherOrder.setUserId(userId);
// 优惠券id直接根据传入的即可
voucherOrder.setVoucherId(voucherId);
save(voucherOrder);
// 返回订单编号
return Result.ok(orderId);
}
}写到这里还和秒杀优惠券没什么关系,只是可以下单了
但根据实际情况来说,这种限时的优惠活动一定会导致高并发,那么就不能忽视线程安全问题。
超卖问题及解决方案
这里涉及到的超卖问题也是经典的线程安全问题
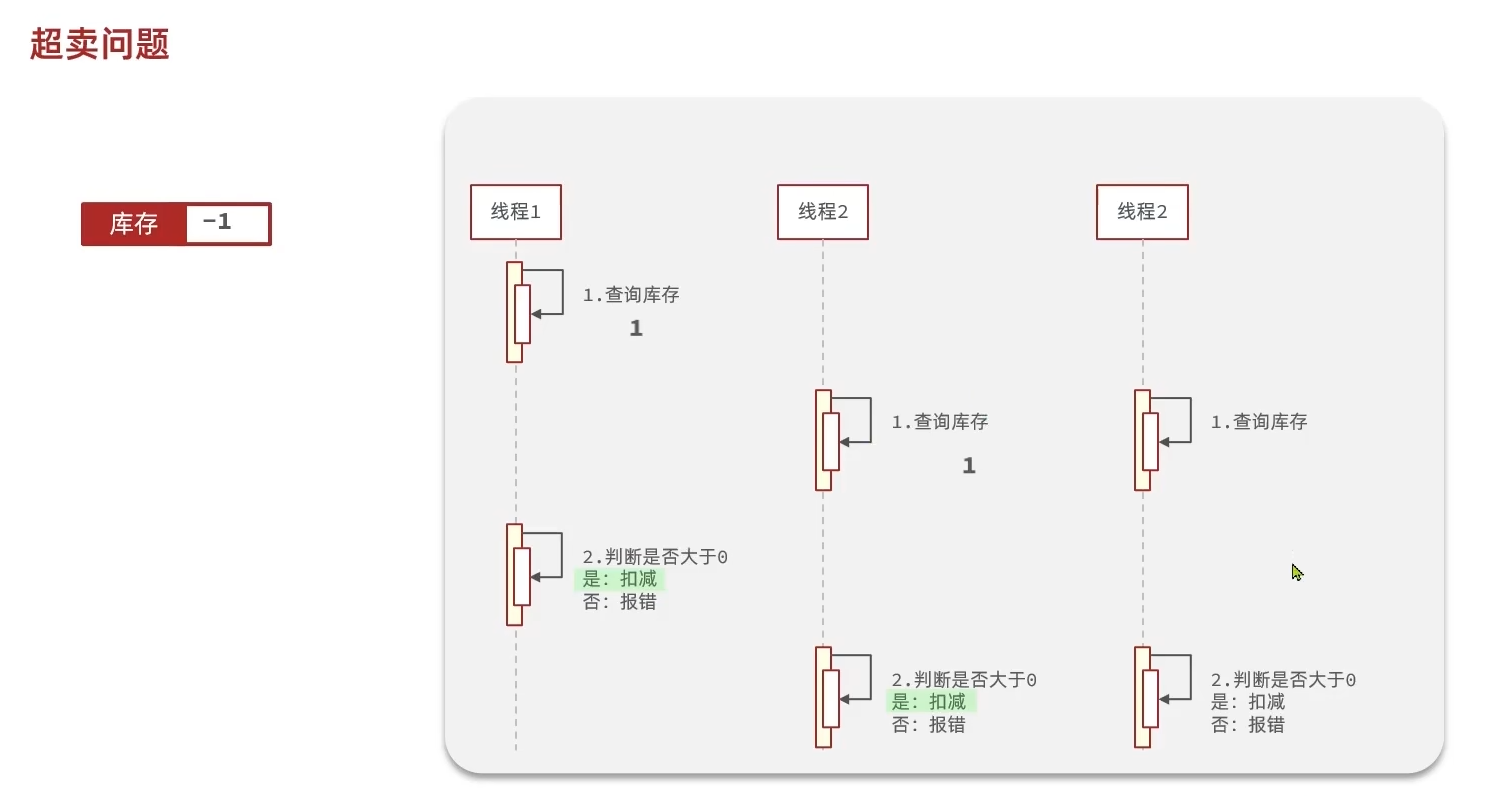
简单来说,无法保证多个线程的执行顺序如我们所愿,根据执行顺序不同,它们可能会产生很多奇葩的错误结果
多线程并发问题解决方案一般来说就是加锁,而锁的设计理念分为悲观锁和乐观锁:

对于高并发而言,悲观锁的性能较差,不太适合作为解决方案,这里学习的是乐观锁
乐观锁的核心设计问题就在于如何“在更新数据时去判断有没有其它线程对数据做了修改”,有很多实现的方案,这里我采用的是加一个“版本号”,辅助以SQL条件判断,用于鉴别当前操作的数据是否和之前查到的一致
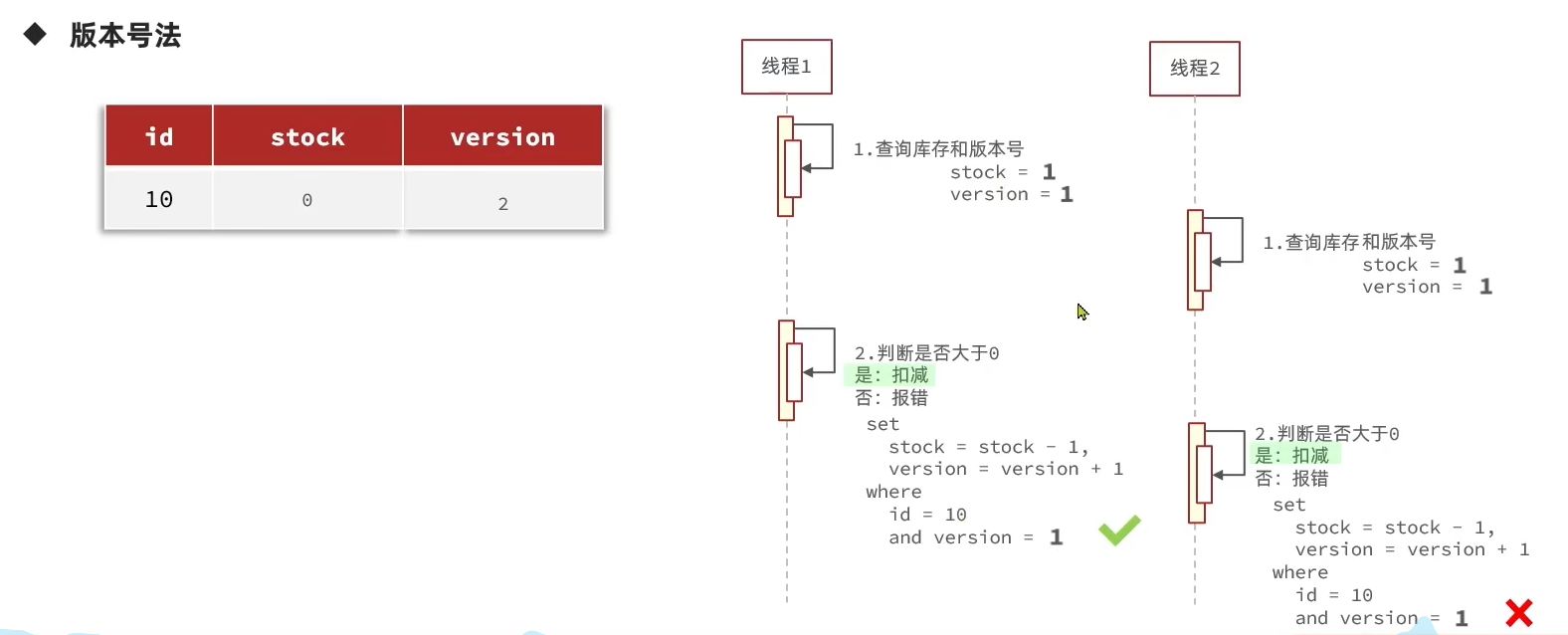
版本号是一个数据库字段,每次操作数据的时候就要把它做一个变化,以表示这个数据被操作了
而同时可以发现,stock字段被操作的时候就会做一个变化,那么在现在这个场景下,我们就可以用这个数据本身去做它的版本号而不用引入新的字段,本质上是 CAS(Compare And Swap)思想在数据库层的体现
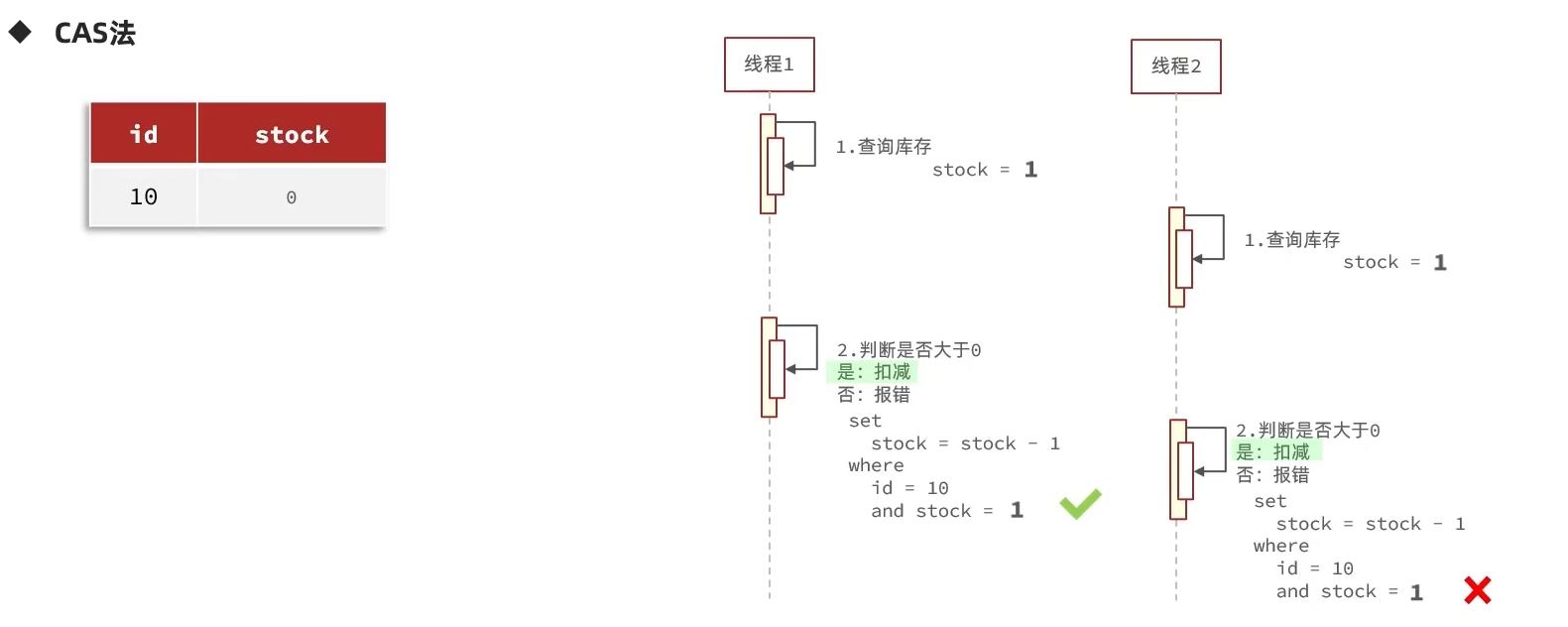
结合上述分析,这里要修改一下代码
一开始改成了
boolean success = seckillVoucherService.update()
.setSql("stock = stock - 1")
.eq("voucher_id", voucherId).eq("stock",voucher.getStock()).update();后面经过测试,发现大部分线程会获取失败。原因是乐观锁的设计原理:只要发现数据被修改了,那么就认为不安全,拒绝访问
那么这里的判断条件其实是有误的,我们实际上想解决的问题是超卖而不是不让同步卖出。按照上述写法会导致大部分同步线程都执行失败,表现出异常率过高
所以这里应该改成:
boolean success = seckillVoucherService.update()
.setSql("stock = stock - 1")
.eq("voucher_id", voucherId).gt("stock",0).update();也就是只要查到的库存数大于0就允许卖出
一人一单
根据实际业务需求,有代码思路如下:
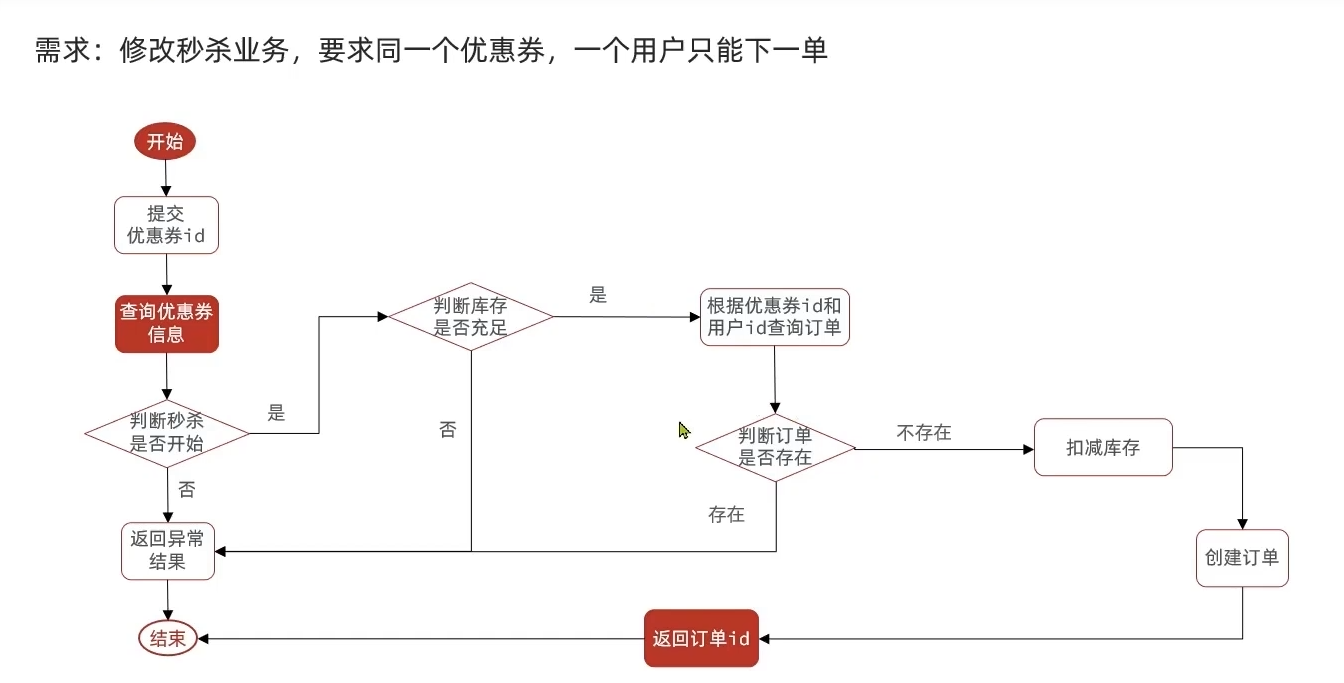
这里仍然会涉及多线程并发安全问题,所以需要加锁。由于乐观锁是在更新过程中适用,因此这里用到的是悲观锁。由于这里我还没怎么学过多线程,也没有搞过分布式集群,所以下面都是基于单服务器来理解的
一开始写出来的代码长这样,我把主要逻辑移到了一个方法里面,然后对方法加了锁
@Transactional
public synchronized Result createVoucherOrder(Long voucherId) {
// 判断该用户是否已经买过
Long userId = UserHolder.getUser().getId();
int count = query().eq("user_id", userId).eq("voucher_id", voucherId).count();
if (count > 0){
return Result.fail("用户已购买过一次!");
}
// 先让库存数减一
boolean success = seckillVoucherService.update()
.setSql("stock = stock - 1")
.eq("voucher_id", voucherId).gt("stock",0).update();
if (!success){
// 扣减库存失败,一般认为也是库存不足
return Result.fail("库存不足");
}
// 创建订单
VoucherOrder voucherOrder = new VoucherOrder();
// 获取订单id,用前面的全局id生成器
long orderId = redisIdWorker.nextId("order");
voucherOrder.setId(orderId);
voucherOrder.setUserId(userId);
// 优惠券id直接根据传入的即可
voucherOrder.setVoucherId(voucherId);
save(voucherOrder);
// 返回订单编号
return Result.ok(orderId);
}如果是单JVM这样写其实功能没有问题,可以保证线程安全了
但是把锁加到方法上,就意味着无论多少个线程(即使是多个不同用户)过来,它们都只能一个个的串行执行方法,效率大打折扣,因为它们拿到的都是同一把锁
根据上述分析,可以把代码改为:
@Transactional
public Result createVoucherOrder(Long voucherId) {
// 判断该用户是否已经买过
Long userId = UserHolder.getUser().getId();
synchronized (userId.toString().intern()) {
int count = query().eq("user_id", userId).eq("voucher_id", voucherId).count();
if (count > 0) {
return Result.fail("用户已购买过一次!");
}
// 先让库存数减一
boolean success = seckillVoucherService.update()
.setSql("stock = stock - 1")
.eq("voucher_id", voucherId).gt("stock", 0).update();
if (!success) {
// 扣减库存失败,一般认为也是库存不足
return Result.fail("库存不足");
}
// 创建订单
VoucherOrder voucherOrder = new VoucherOrder();
// 获取订单id,用前面的全局id生成器
long orderId = redisIdWorker.nextId("order");
voucherOrder.setId(orderId);
voucherOrder.setUserId(userId);
// 优惠券id直接根据传入的即可
voucherOrder.setVoucherId(voucherId);
save(voucherOrder);
// 返回订单编号
return Result.ok(orderId);
}
}这一版代码使得不同的用户能拿到不同的锁,提高了并发性能
注意这里的userId.toString().intern()。因为toString方法的底层是new String(),返回的是引用地址值(每次都创建新对象,导致地址值不一致)而不是实际值(synchronized内部比较的是引用地址值)。但String.intern() 的语义是返回字符串常量池中“内容相同的那个唯一 String 对象”,这就可以保证同一个userId对象一定能得到true的结果
似乎可以了,跑一下测试看看:
@Resource
private IVoucherOrderService voucherOrderService;
@Test
public void testConcurrentCreateVoucherOrder() throws InterruptedException {
int threadCount = 100;
ExecutorService executorService = Executors.newFixedThreadPool(20);
CountDownLatch latch = new CountDownLatch(threadCount);
Long voucherId = 11L; // 数据库里真实存在的秒杀券 ID
Long userId = 10001L; // 随便写一个userId模拟同一个用户
for (int i = 0; i < threadCount; i++) {
executorService.submit(() -> {
try {
// 模拟登录逻辑,保证ThreadLocal里面有User信息
UserDTO user = new UserDTO();
user.setId(userId);
UserHolder.saveUser(user);
Result result = voucherOrderService.seckillVoucher(voucherId);
if (result.getSuccess()) {
System.out.println(Thread.currentThread().getName()
+ " SUCCESS, orderId=" + result.getData());
} else {
System.out.println(Thread.currentThread().getName()
+ " FAIL, reason=" + result.getErrorMsg());
}
} finally {
// 必须清理ThreadLocal
UserHolder.removeUser();
latch.countDown();
}
});
}
latch.await();
}
回去看看数据库和日志,可以发现同一个用户买了10个库存。问题依然没有解决
回看一下代码,可以发现事物@Transactional是由spring管理的,因此只有当函数结束后才可以被提交。但是锁是在函数内部的,因此只有锁先被释放,事物才可以提交
那么在锁被释放到事物提交的这段时间,很有可能又有其它线程获取锁并执行完createVoucherOrder函数
解决方法也很简单,把锁移到外面,让事物先提交就行了
Long userId = UserHolder.getUser().getId();
synchronized (userId.toString().intern()) {
return createVoucherOrder(voucherId,userId);
}但是这样忽略了一个重要的问题:事务失效
可以看到代码在createVoucherOrder方法的上面加了@Transactional事务,但是由于锁包括的那一段属于同类内部调用自己方法,因此会导致事务失效
原因是Spring 代理只拦截 通过代理对象调用的方法,而这里属于内部调用,不会经过代理,因此事务不会被拦截和开启
回忆一下spring的事务相关概念:
1️⃣ 核心思想 Spring 的事务管理是通过 AOP(面向切面编程)代理来实现的。
- @Transactional 本质上是告诉 Spring:“在这个方法执行前后加上事务逻辑”。
- Spring 会生成一个 代理对象,代理对象在方法调用时,会自动处理事务的开启、提交或回滚。
2️⃣ 代理对象
- Spring 为我们写的类生成的一个“包装类”:
- 如果类实现了接口 → JDK 动态代理
- 如果类没有接口 → CGLIB 继承生成代理类
- 我们拿到的 Bean,其实是代理对象,而不是我们写的原始对象。
- 代理对象在方法调用时,先执行事务逻辑,然后调用原始方法,方法返回后再处理事务提交或回滚。
调用流程:
调用 Bean 方法 -> 代理对象 intercept -> 开启事务 -> 调用原始方法 -> 方法返回 -> 提交/回滚事务3️⃣ 事务生效条件
- 事务只在 通过代理对象调用的方法 时生效
- 内部调用(同一个类里直接 this.method())不会经过代理 → 事务失效
- 解决方法:
- 通过 AopContext.currentProxy() 获取代理对象,再调用方法
- 或者把调用移到外部类
4️⃣ 事务的实际行为
- 开启事务:在方法开始,Spring 创建或加入一个数据库事务
- 提交事务:方法正常结束,事务提交
- 回滚事务:方法抛出异常,事务回滚(默认只回滚 RuntimeException)
在这里调用的方法createVoucherOrder就是属于内部调用,不会走代理对象,也就导致上面加的事务没啥用
这里的改进方法就是获取代理对象再进行调用,要做三件事:
1️⃣ 在启动类添加注解@EnableAspectJAutoProxy(exposeProxy = true)
- 作用:开启 Spring AOP 的 基于代理的切面支持(事务本质上是切面编程思想的运用)。
- 参数
exposeProxy = true的意义:- 默认情况下,Spring 只在 外部 Bean 调用代理方法时才生效事务。
exposeProxy = true会把当前代理对象放到 ThreadLocal,可以通过AopContext.currentProxy()拿到。
- 为什么需要:
- 在同一个类内部调用
createVoucherOrder并让事务生效,必须通过代理对象调用,而不是直接this.createVoucherOrder()。 exposeProxy = true就是为AopContext.currentProxy()提供前提。否则无法获取到代理对象
- 在同一个类内部调用
2️⃣ 改进Service的代码
将锁块内部代码改为:
synchronized (userId.toString().intern()) {
IVoucherOrderService proxy = (IVoucherOrderService) AopContext.currentProxy();
return proxy.createVoucherOrder(voucherId,userId);
}-
作用:拿到 当前 Bean 的代理对象,调用代理对象的
createVoucherOrder,触发 Spring 的事务切面。 -
原理:
- 事务是通过代理实现的,只有通过代理对象调用方法,事务才会生效。
- 内部直接调用
createVoucherOrder()相当于this.createVoucherOrder(),不会经过代理,事务切面不会触发。
-
额外补充:
-
如果不加
@EnableAspectJAutoProxy(exposeProxy = true),AopContext.currentProxy()一定拿不到代理对象,测试方法的100个线程没有一个能成功下单。原因很简单,Spring 默认的 AOP 行为是:-
代理对象只对“外部调用”可见
-
方法内部调用时,不暴露代理对象给当前线程
也就是它默认当前线程的 ThreadLocal 是不填值的,我们需要手动让spring知道应该往里面放代理对象
-
-
前面提到Spring的代理方式有两种,根据该类有没有实现接口来分。这里的类实现了Service层接口,所以spring采用了JDK 动态代理方式。而JDK 动态代理生成的对象不是
VoucherOrderServiceImpl的子类,它只实现接口IVoucherOrderService(给某一个具体 Bean 实例生成一个只实现该接口的代理对象,对象是一个具体的、正确的且符合我们需要的Bean,只是通过接口表现出来)。当然也可以强制拿实体类VoucherOrderServiceImpl的代理对象,但没必要
-
3️⃣ 引入相关依赖
需要在pom文件里面引入依赖:
<dependency>
<groupId>org.aspectj</groupId>
<artifactId>aspectjweaver</artifactId>
</dependency>暂时不用了解那么多,只需要知道Spring 的注解式 AOP(包括事务)底层依赖 AspectJ 的织入能力即可
分布式锁
前一节学的“一人一单”问题最终用了事务+悲观锁解决了,但那个方法只能解决单JVM下的线程安全问题
但是对于多进程的集群而言每个进程都有自己的锁监视器,也就是说锁无法再限制多个线程了,如下图:
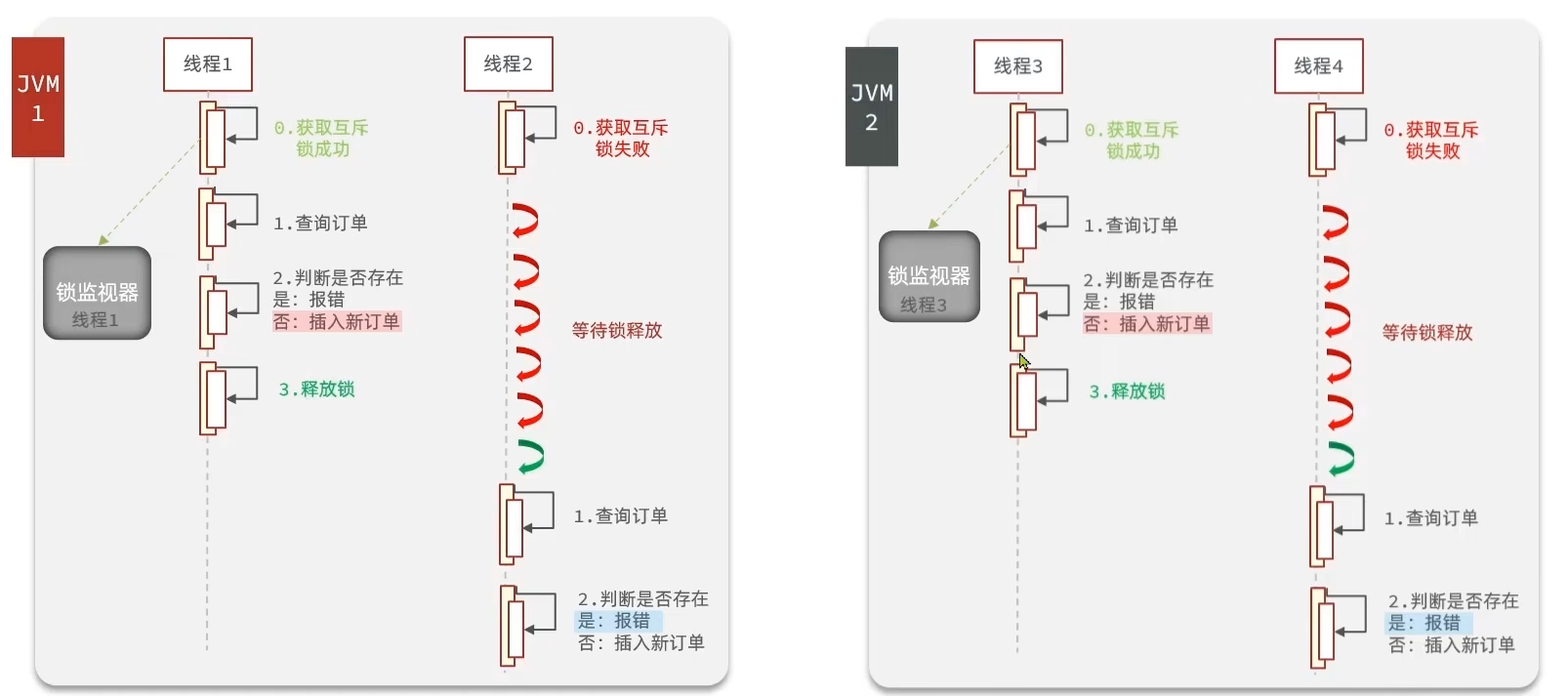
那么理所应当的可以想到解决方案,用一个所有进程共同的锁监视器即可
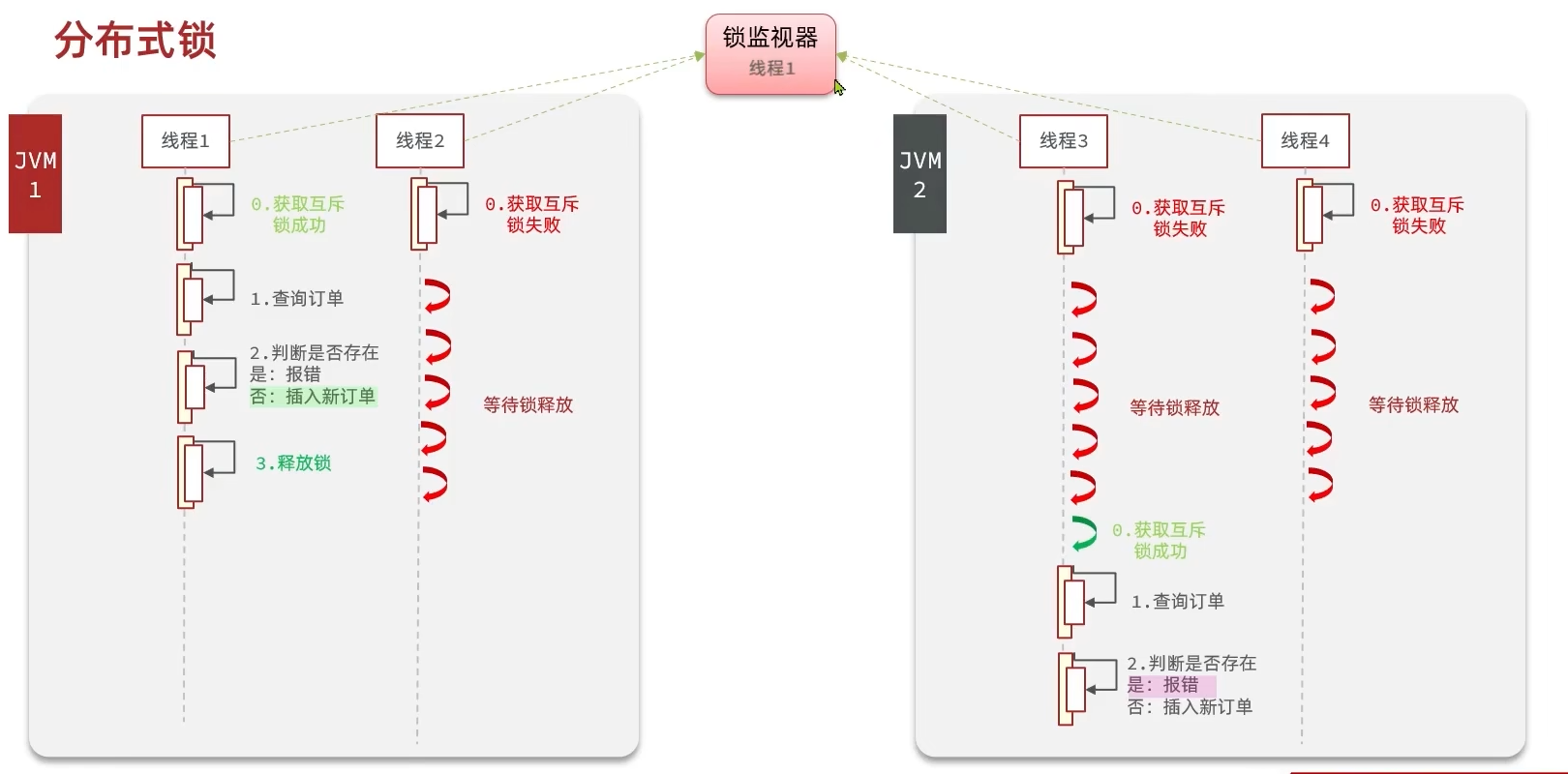
继续转换问题,那么现在就要寻找到一个共同锁监视器的实现对象,它应该满足以下几点:
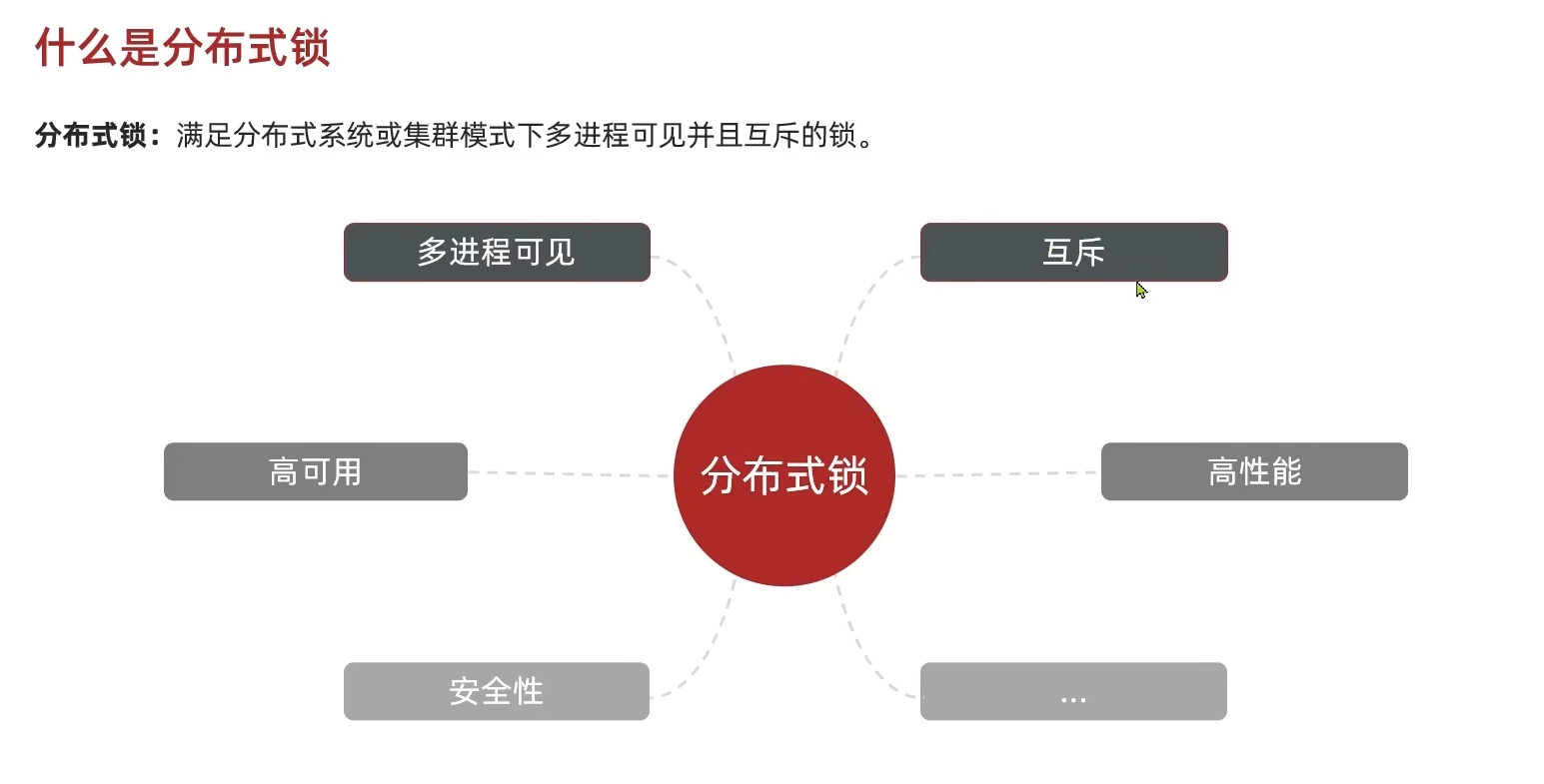
redis、mysql都可以作为实现对象,还有一个不熟悉的zookeeper(是一个分布式协调服务,暂时不用在意)。分析比较一下它们实现上述功能的方案差异
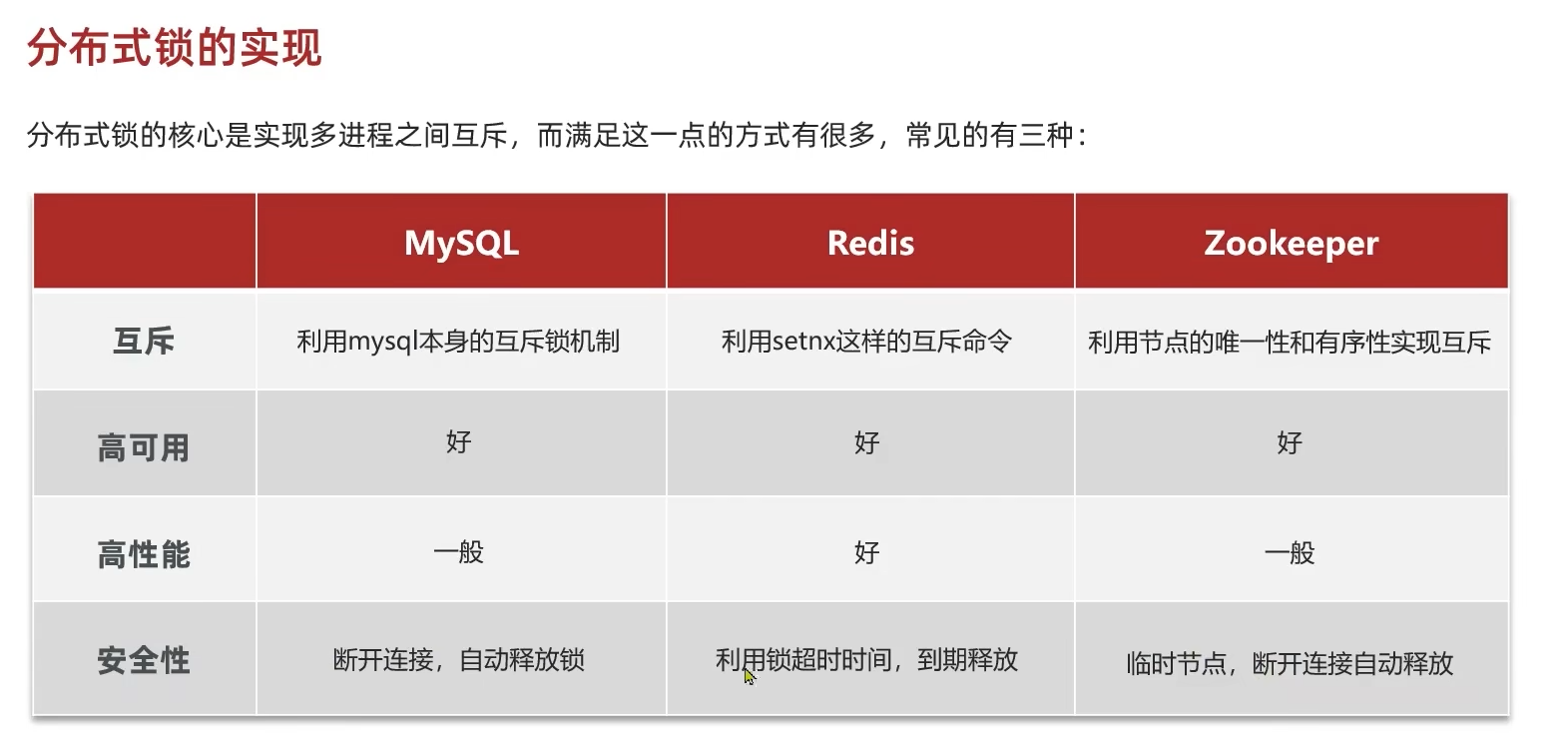
这个教程主要是学习redis的,因此后面的分布式锁实现方案也用的是redis
Redis分布式锁实现思路
基于SETNX实现
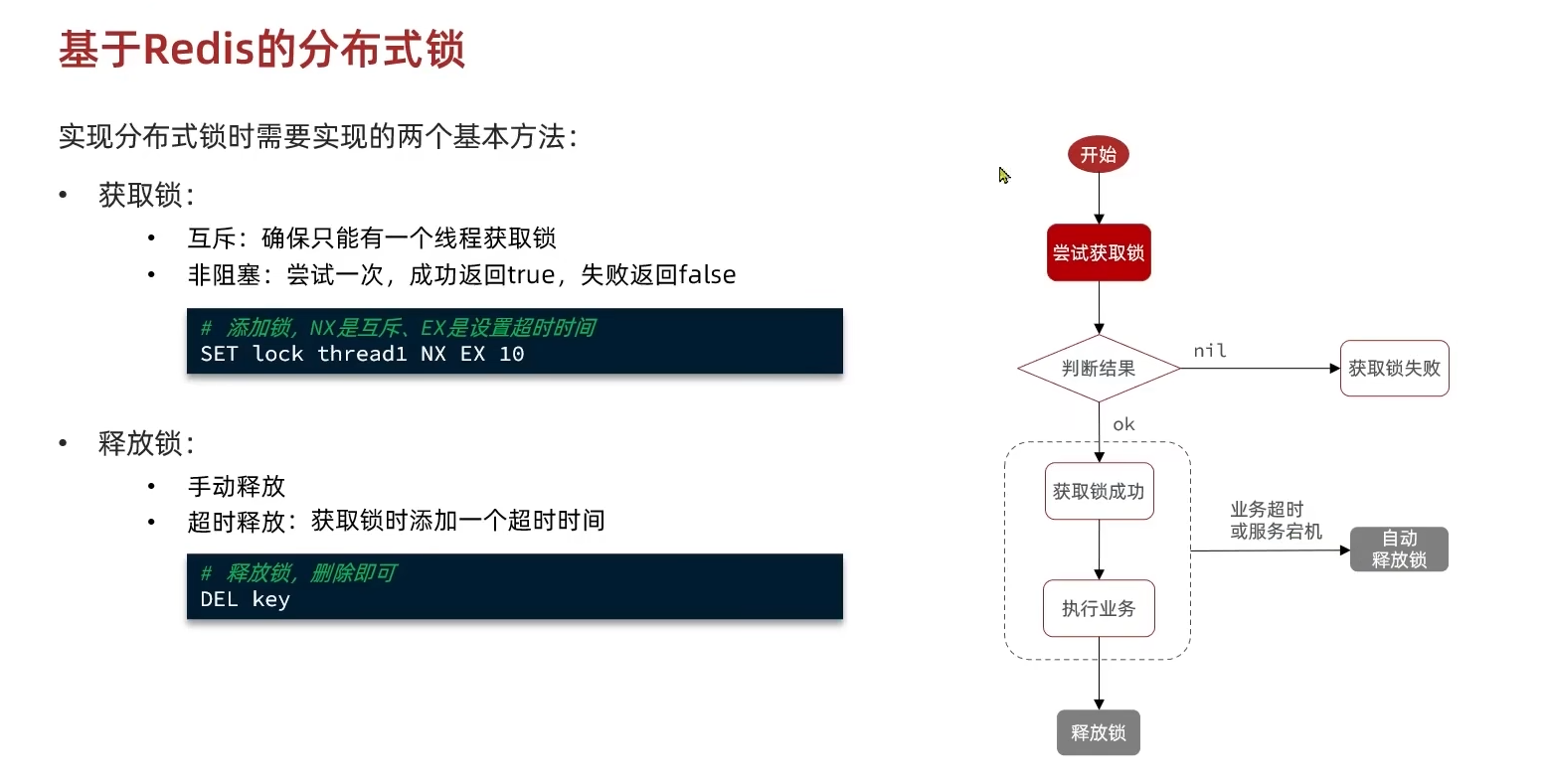
这里用SET lock thread1 NX EX 10而不用SETNX lock thread1 + expire lock 10的原因是为了保证获取锁和加过期时间这两步操作的原子性
具体实现代码
初版简易代码及问题分析
按照上面的思想,定义出接口,然后用类去实现

这里就可以写出来一段能用的简略代码了。首先写一个管理锁的生成和释放的类:
package com.hmdp.utils;
import org.springframework.data.redis.core.StringRedisTemplate;
import java.util.concurrent.TimeUnit;
public class SimpleRedisLock implements ILock{
// 可以把userId用来做保证唯一性的key
private String name;
private StringRedisTemplate stringRedisTemplate;
public SimpleRedisLock(String name, StringRedisTemplate stringRedisTemplate){
this.name = name;
this.stringRedisTemplate = stringRedisTemplate;
}
private static final String KEY_PREFIX = "lock:";
@Override
public boolean tryLock(long timeoutSec) {
// 获取线程标识
long threadId = Thread.currentThread().getId();
// 获取锁
Boolean success = stringRedisTemplate.opsForValue().setIfAbsent(KEY_PREFIX + name, threadId + "", timeoutSec, TimeUnit.SECONDS);
// 防止自动拆箱出现空指针
return Boolean.TRUE.equals(success);
}
@Override
public void unlock() {
stringRedisTemplate.delete(KEY_PREFIX + name);
}
}然后修改一下下单的VoucherOrderServiceImpl类中的加锁逻辑,把原来的:
synchronized (userId.toString().intern()) {
IVoucherOrderService proxy = (IVoucherOrderService) AopContext.currentProxy();
return proxy.createVoucherOrder(voucherId,userId);
}改成:
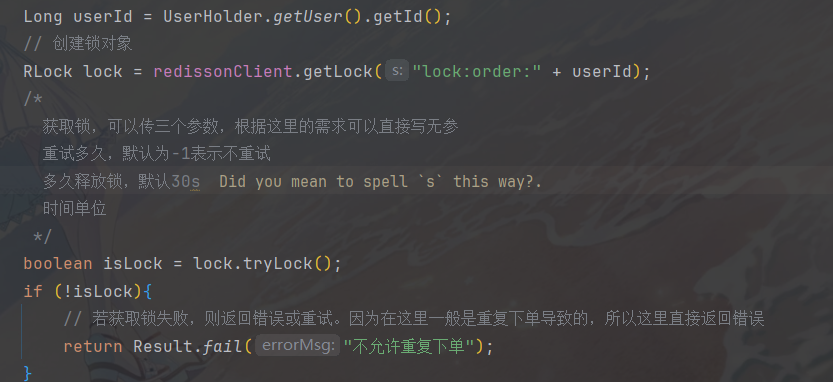
// 创建锁对象
SimpleRedisLock lock = new SimpleRedisLock("order" + userId, stringRedisTemplate);
// 从锁对象获取锁
boolean isLock = lock.tryLock(1200);
if (!isLock){
// 若获取锁失败,则返回错误或重试。这里直接返回错误(为了防止超卖问题)
return Result.fail("不允许重复下单");
}
try{
IVoucherOrderService proxy = (IVoucherOrderService) AopContext.currentProxy();
return proxy.createVoucherOrder(voucherId,userId);
}finally {
// 释放锁
lock.unlock();
}但是可以发现这个时候的代码还会存在一个问题,具体如下面的极端情况示例:
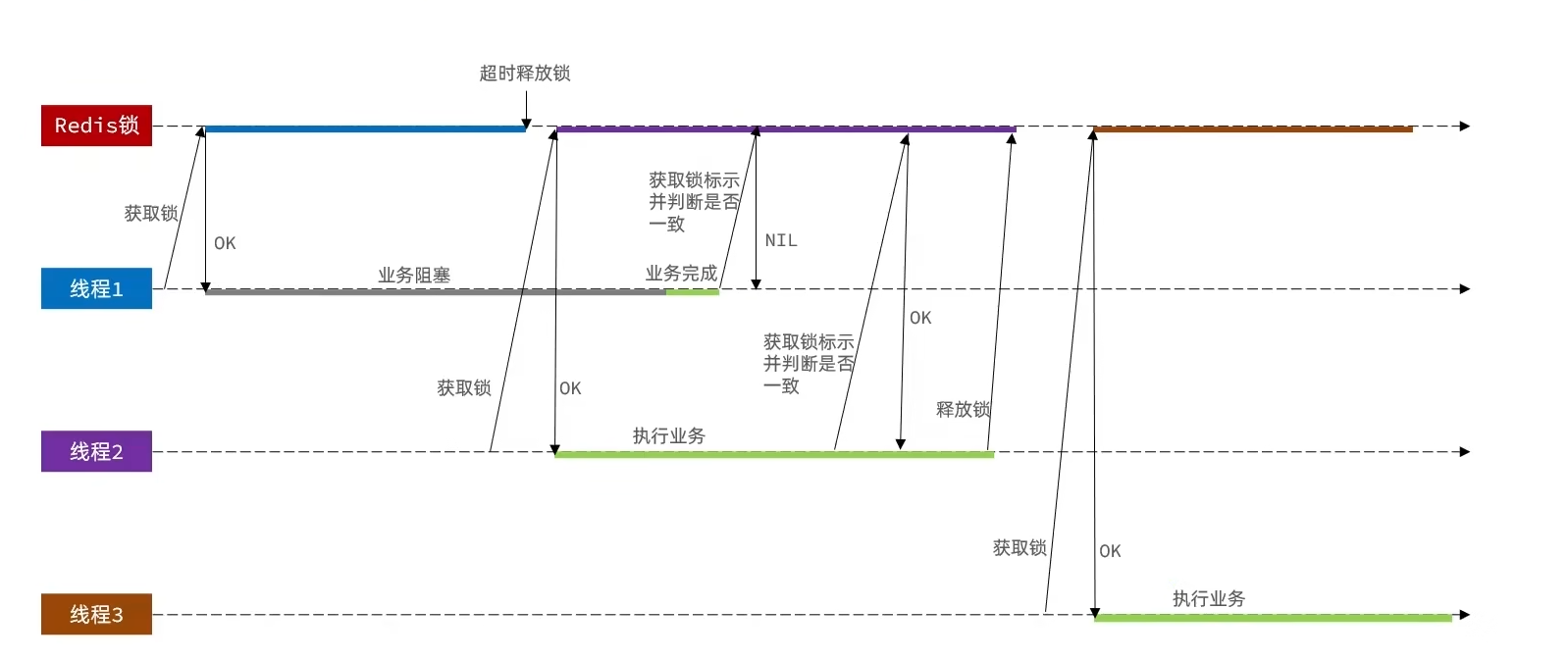
核心问题就是一个线程在释放锁的时候没有进行检查,可能释放的并不是自己的锁。解决方法也很简单,在释放锁之前进行一次检查即可。那么流程就变成如下这样:
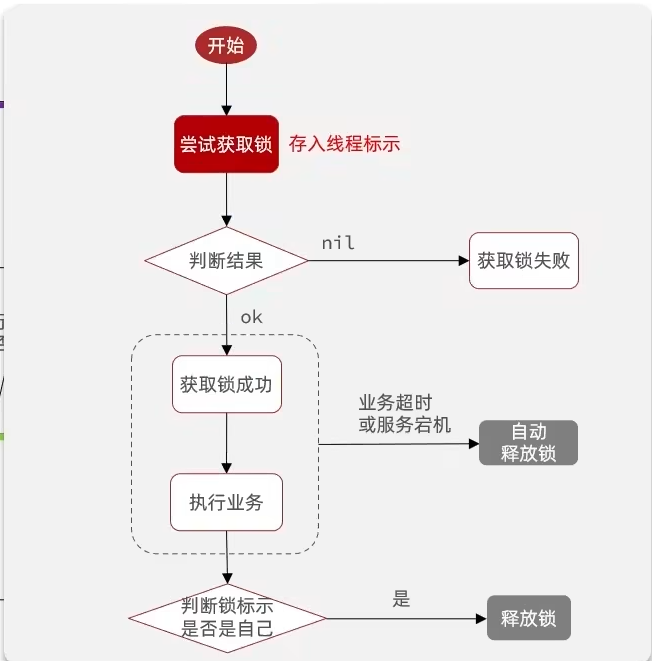
也就是说,要给每个JVM的每个线程添加的锁给上一个特定的标识。在集群式环境下会有多个JVM,那么最开始单纯地用线程ID来作为线程标识就不可行了(因为线程ID是有规律的,多个JVM可能会产生相同的线程ID)。因此这里采用UUID+线程ID来做标识,保证了锁的唯一性
将SimpleRedisLock改为了:
package com.hmdp.utils;
import cn.hutool.core.lang.UUID;
import org.springframework.data.redis.core.StringRedisTemplate;
import java.util.concurrent.TimeUnit;
public class SimpleRedisLock implements ILock{
// 可以把userId用来做保证唯一性的key
private String name;
private StringRedisTemplate stringRedisTemplate;
public SimpleRedisLock(String name, StringRedisTemplate stringRedisTemplate){
this.name = name;
this.stringRedisTemplate = stringRedisTemplate;
}
private static final String KEY_PREFIX = "lock:";
private static final String ID_PREFIX = UUID.randomUUID().toString(true) + "-";
// 获取线程标识
String threadId = ID_PREFIX + Thread.currentThread().getId();
@Override
public boolean tryLock(long timeoutSec) {
// 获取锁
Boolean success = stringRedisTemplate.opsForValue()
.setIfAbsent(KEY_PREFIX + name, threadId, timeoutSec, TimeUnit.SECONDS);
// 防止自动拆箱出现空指针
return Boolean.TRUE.equals(success);
}
@Override
public void unlock() {
// 用key去redis数据库找value再和线程标识比对,若这两个相等则可以证明是自己的锁,可以释放,否则不应该释放
String id = stringRedisTemplate.opsForValue().get(KEY_PREFIX + name);
if (threadId.equals(id)){
stringRedisTemplate.delete(KEY_PREFIX + name);
}
}
}自己也起了两个端口,用postman测了,没有问题。这里因为摆烂太久导致时间跨度有点大,甚至忘了拦截器那边的流程,折腾redis和token折腾了半天。。
Lua脚本解决误删问题
即使做了判断,这里仍然会有某些极端情况导致误删,如下图所示,若线程1在判断锁标识成功之后恰好因为JVM的原因(一般来说是JVM的垃圾回收机制GC导致的STW停顿,在高并发场景下停十几秒是很常见的)而阻塞,导致释放锁的操作没有完成。若此时阻塞的时间过长导致锁自动超时释放,其它线程可以获取锁,当线程1阻塞解除之后再次释放锁,就会发生误删问题
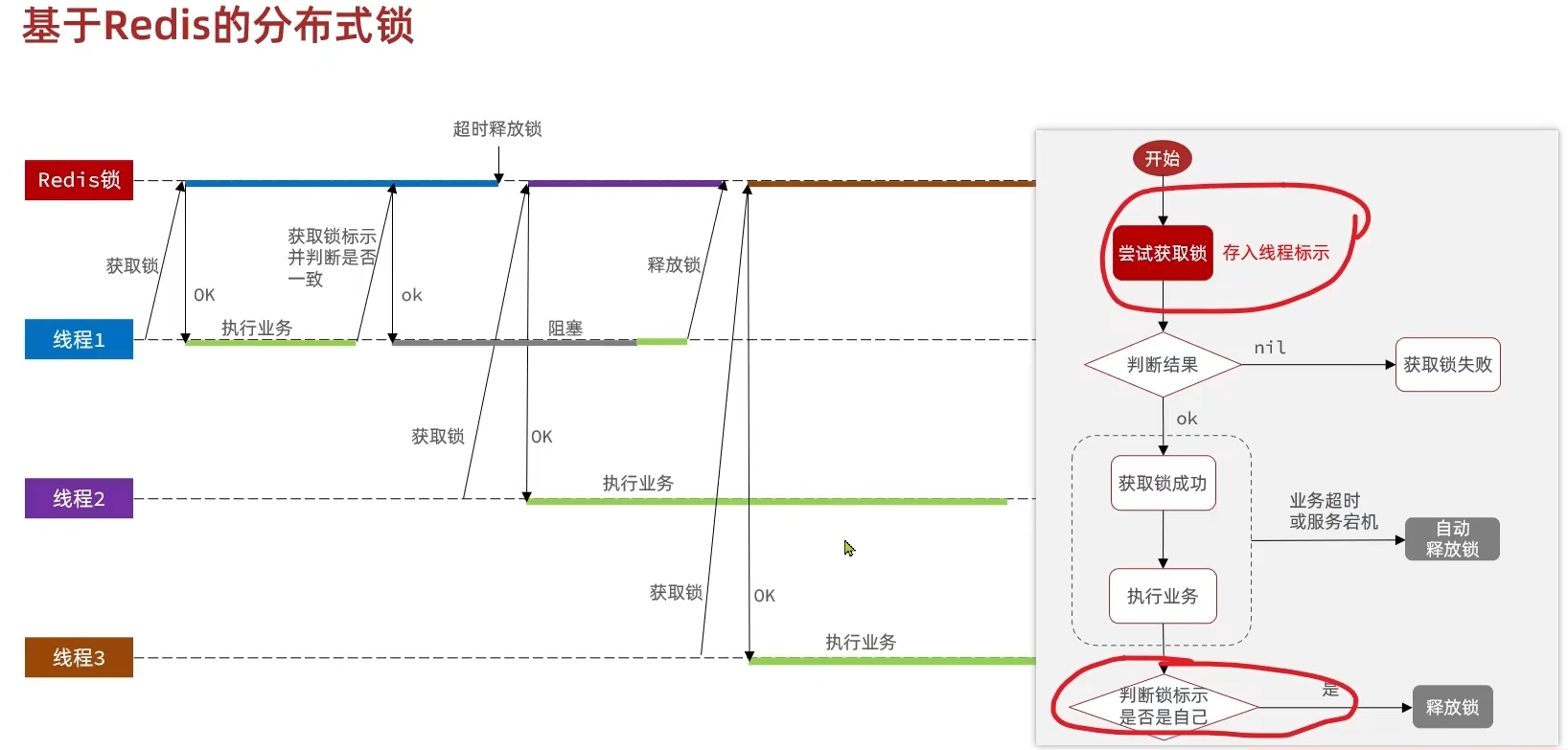
这个问题出现的根本原因是判断锁标识和释放锁是分开操作的,若能保证它们是原子性操作则可以解决这个问题。这里用到前面互斥锁那里用过的Lua脚本,那次用是直接AI给的代码,这次再来详细复习它的相关函数API
Redis提供了调用函数,语法为:
redis.call('命令名称','key','其它参数')如set name jack:
redis.call('set','name','jack')可以在redis的客户端控制台用eval命令执行脚本,举个例子为:
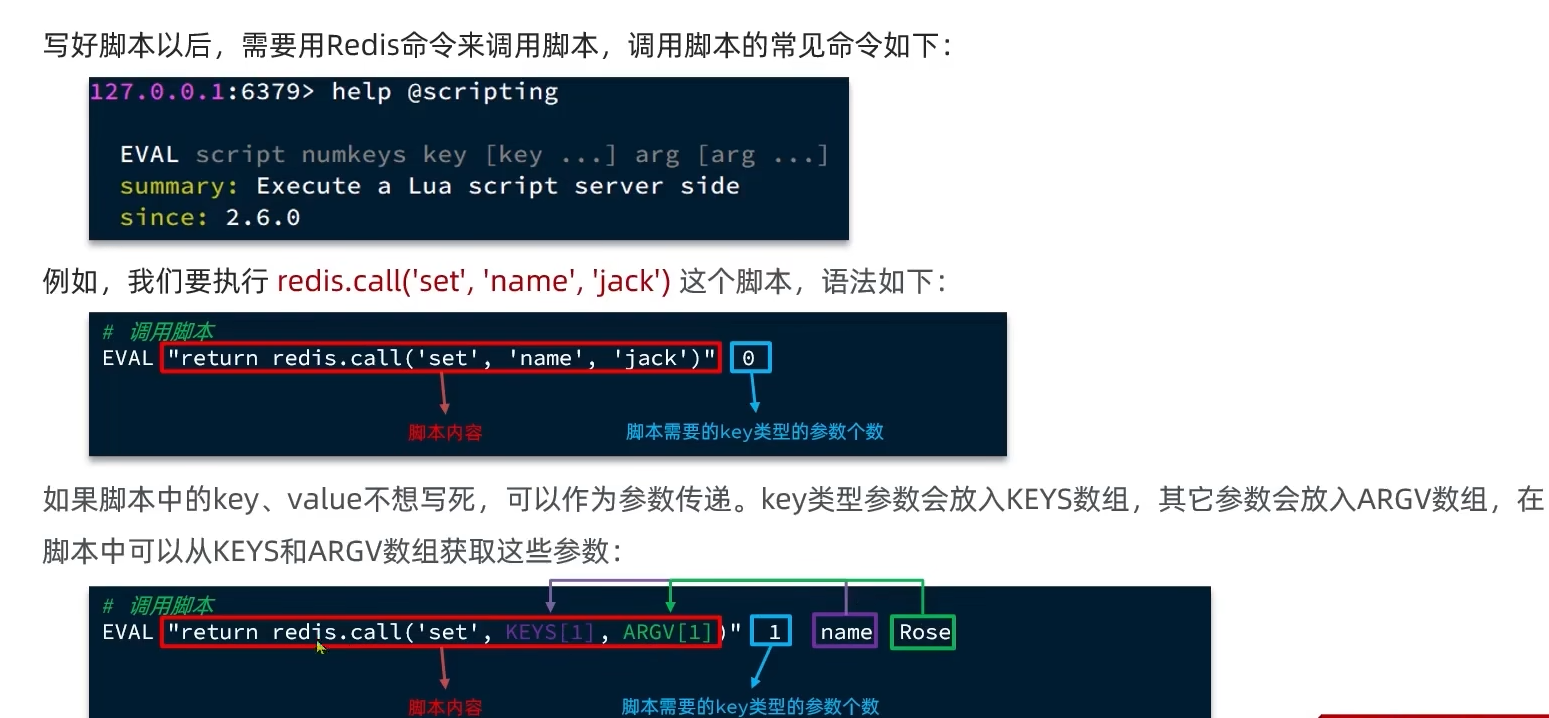
eval "return redis.call('set', 'name', 'jack')" 0后面的0表示key类型的参数有0个(在这里参数分为key类型参数和其它类型参数),控制台会返回“OK”,然后可以看到name被存进去了
还可以在Lua脚本里面加参数,具体规则和例子如下图:
Lua里面数组的角标是从1开始的而非0
那么可以写一段简易可用的Lua代码:
-- 获取锁中的线程标识 get key
local id = redis.call('get',KEYS[1])
-- 比较线程标识与锁中的标识是否一致
if(id == ARGV[1]) then
-- 释放锁 del key
return redis.call('del',KEYS[1])
end
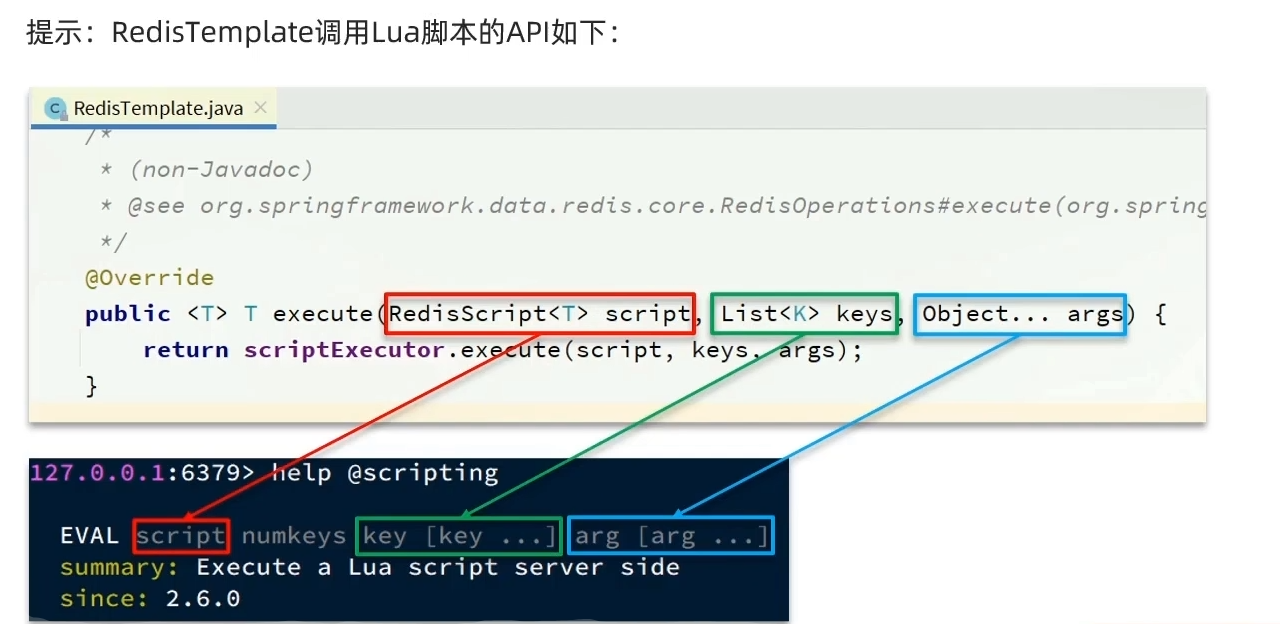
return 0Java调用Lua脚本,可以用StringRedisTemplete提供的API:
将Lua脚本写到resources文件夹下的新建文件unlock.lua,尽量减少代码耦合度,最终代码改为:
package com.hmdp.utils;
import cn.hutool.core.lang.UUID;
import org.springframework.core.io.ClassPathResource;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.data.redis.core.script.DefaultRedisScript;
import java.util.Collections;
import java.util.concurrent.TimeUnit;
public class SimpleRedisLock implements ILock{
// 可以把userId用来做保证唯一性的key
private String name;
private StringRedisTemplate stringRedisTemplate;
public SimpleRedisLock(String name, StringRedisTemplate stringRedisTemplate){
this.name = name;
this.stringRedisTemplate = stringRedisTemplate;
}
private static final String KEY_PREFIX = "lock:";
private static final String ID_PREFIX = UUID.randomUUID().toString(true) + "-";
// 作为Lua的执行媒介对象
private static final DefaultRedisScript<Long> UNLOCK_SCRIPT;
static{
UNLOCK_SCRIPT = new DefaultRedisScript<>();
UNLOCK_SCRIPT.setLocation(new ClassPathResource("unlock.lua"));
UNLOCK_SCRIPT.setResultType(Long.class);
}
// 获取线程标识
String threadId = ID_PREFIX + Thread.currentThread().getId();
@Override
public boolean tryLock(long timeoutSec) {
// 获取锁
Boolean success = stringRedisTemplate.opsForValue()
.setIfAbsent(KEY_PREFIX + name, threadId, timeoutSec, TimeUnit.SECONDS);
// 防止自动拆箱出现空指针
return Boolean.TRUE.equals(success);
}
@Override
public void unlock() {
// 调用lua脚本
stringRedisTemplate.execute(
UNLOCK_SCRIPT,
Collections.singletonList(KEY_PREFIX + name),
ID_PREFIX + Thread.currentThread().getId()
);
}
}现在来进行测试,这里简述一下测试操作:
-
先进行登录,获得token
-
在IDEA开两个端口,然后打个断点:
 用postman分别发送两个POST请求(Header中记得带上token),路径分别为
用postman分别发送两个POST请求(Header中记得带上token),路径分别为
http://localhost:8081/voucher-order/seckill/11,http://localhost:8082/voucher-order/seckill/11 -
这里要先发第一个请求并步过到if判断这里,可以看到获取到了锁,然后在redis客户端那里把它删掉
-
删掉之后再发第二个端口的请求,一样步过到if判断这里,可以发现两个线程都拿到了锁
-
然后步过第一个线程结束再看看redis客户端,可以看到它没有释放这个锁,步过第二个线程至结束,可以看到锁被正确释放了
经过测试,现代码可以正常执行原下单和防超卖逻辑,也保证了原子性。就先到这里了
Redisson
入门简要
实际上,基于SETNX实现的锁还存在很多问题:

其实随便想想就知道,正常项目开发怎么可能会用自己写的这么简单的锁
有一个专门的项目提供了许多分布式服务,其中也包括各种分布式锁的实现:

接下来改一下原来的锁代码,直接用接口即可,也就几步简单操作,这里就不详细记录了
-
添加依赖
<dependency> <groupId>org.redisson</groupId> <artifactId>redisson</artifactId> <version>3.13.6</version> </dependency> -
写配置类
package com.hmdp.config; import org.redisson.Redisson; import org.redisson.api.RedissonClient; import org.redisson.config.Config; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class RedissonConfig { /** * Redisson工厂类,用于创建RedissonClient类 * @return 配置好的RedissonClient类 */ @Bean public RedissonClient redissonClient(){ // 配置 Config config = new Config(); config.useSingleServer().setAddress("redis://127.0.0.1:6379"); return Redisson.create(config); } } -
改相关使用
去对应的地方改一下即可,代码里都写了注释,这里不赘述
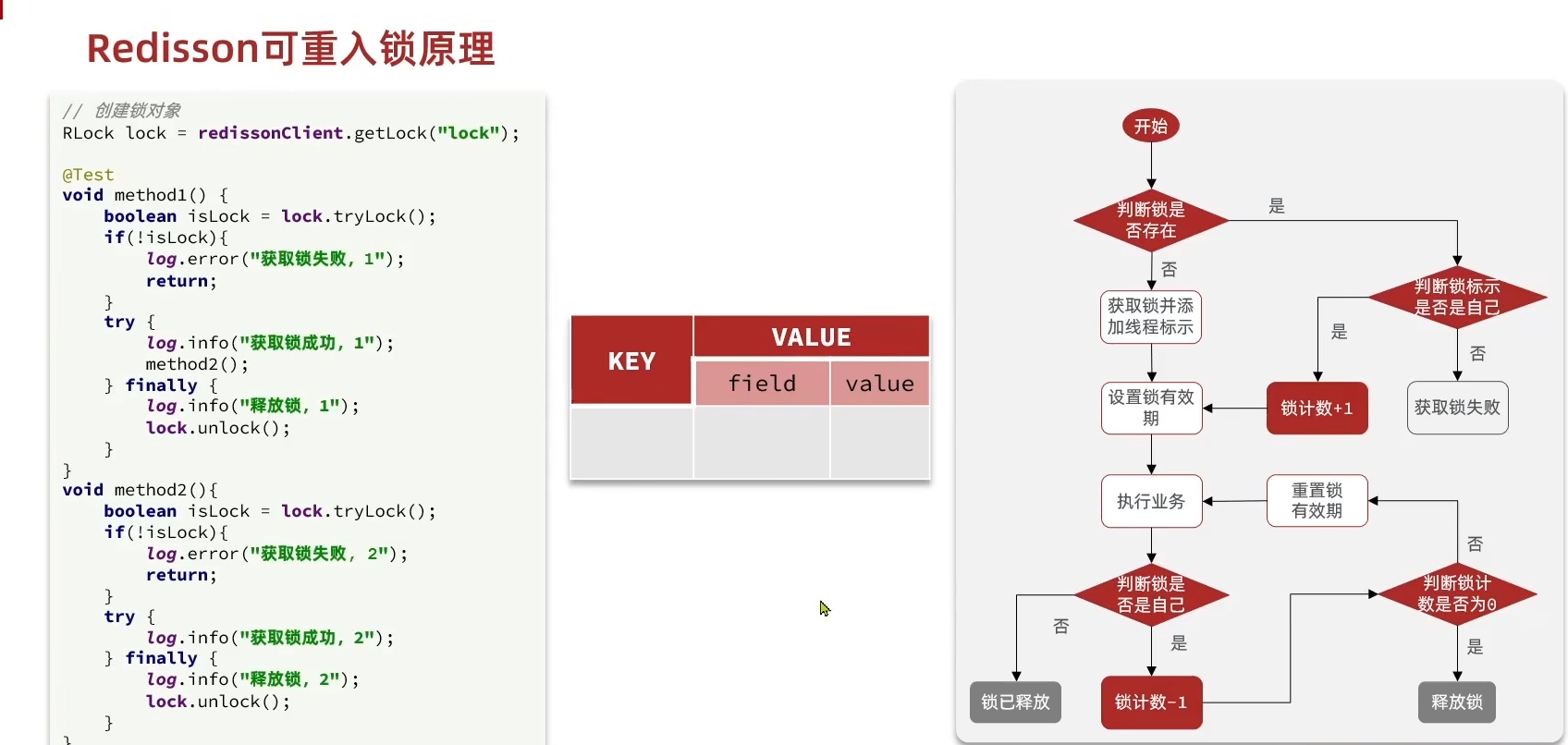
Redisson可重入锁原理
锁键值对中,值的数据类型变成了哈希类型,刚好可以多存储一个锁计数器。
用线程名来作为特定的锁标识,锁标识相同则认为是同一个线程在使用锁,仅对锁计数器操作,当锁计数器重新变为0时释放锁,原理图 如下(左侧为举例代码,右侧为原理图)
锁标识指的是线程名,同一个线程则锁标识相同
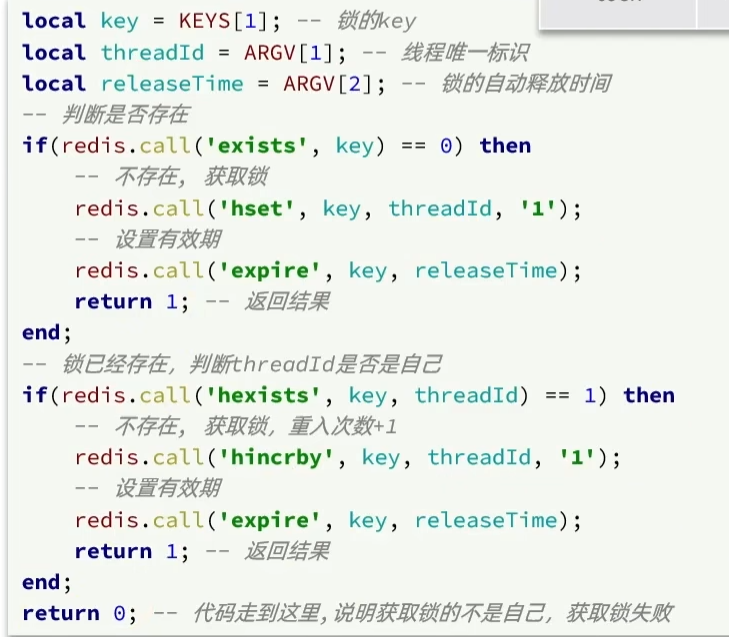
获取锁和释放锁的操作必须保证原子性,因此需要用Lua脚本来实现,这里给出简单逻辑代码
获取锁:
释放锁:
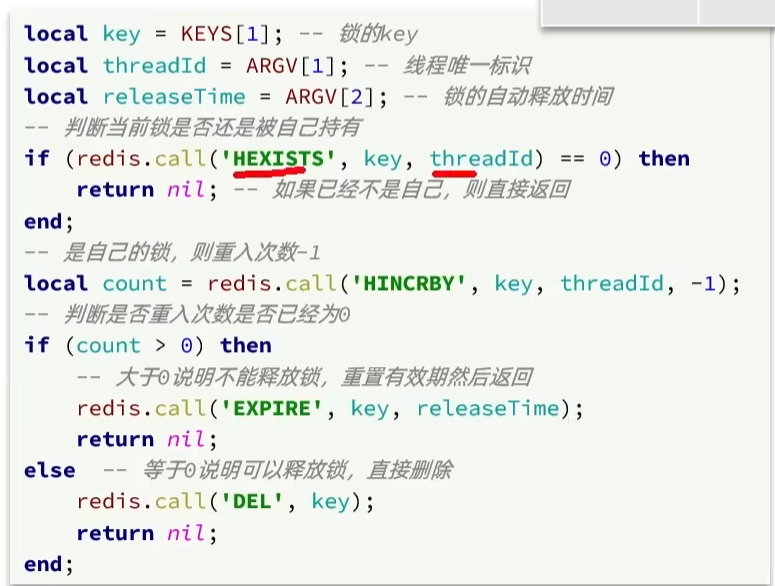
貌似源码里面也是蛮简单的,释放锁:
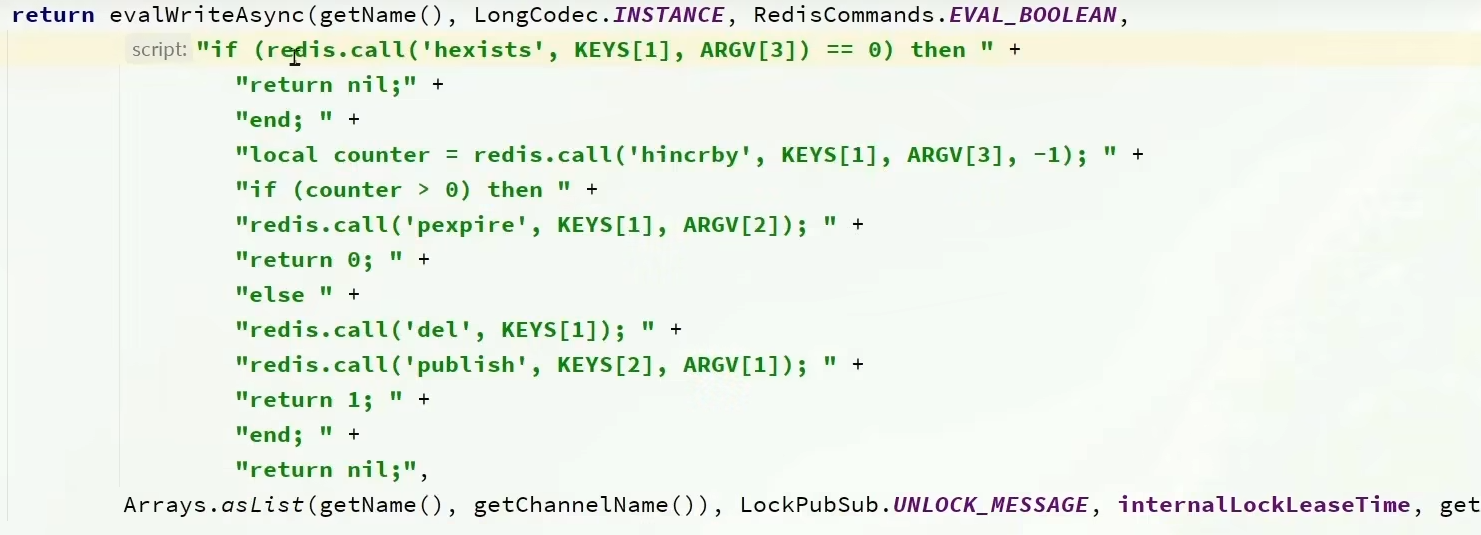
这里还有专门的一节深入了redisson的加锁、释放锁的源码,从源码层面
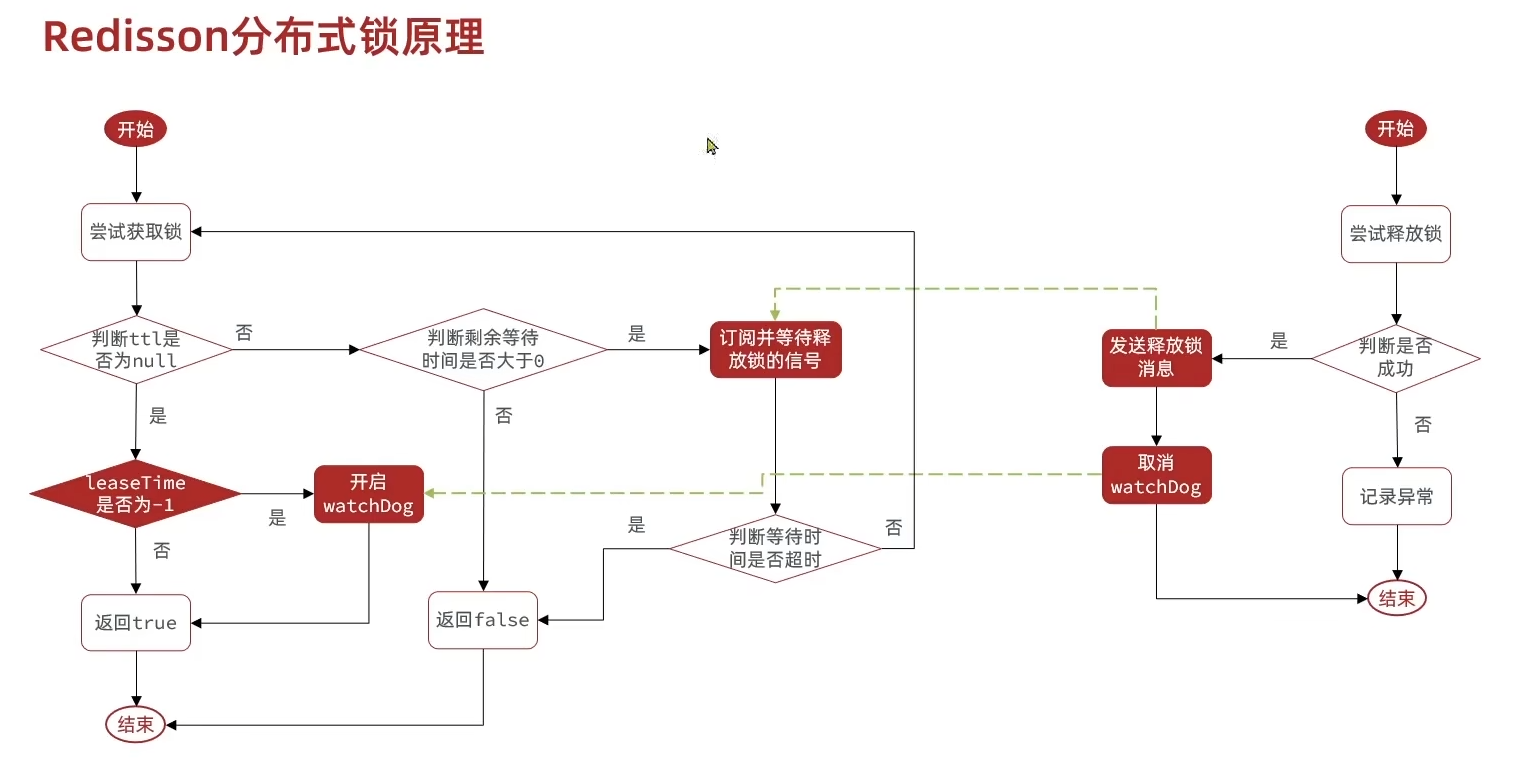
看了一下redisson的分布式锁原理以及是怎么解决那几个问题的(即不可重入、不可重试、超时问题等),感觉没什么记的必要,这里就不过多赘述,随便贴贴吧

至于redisson对于主从一致性的解决方案和源码分析这里也不赘述了,感觉没什么必要(
分布式锁相关实现总结

秒杀优化
分析
回顾一下已经成功加锁的优惠券秒杀逻辑。虽然现在的代码能够安全地完成下单逻辑,但因为在这段过程中过多地对数据库进行读写,以及不断获取和释放分布式锁,从而导致性能极低,应该进行优化
分析一下,导致性能下降的原因主要为:
-
收到所有订单请求之后都要去查询mysql数据库
-
mysql数据库读写的速度较慢,且程序需要等待其返回结果才能继续执行
也就是说,其实导致性能下降的主要原因就是代码多次对mysql数据库进行读写导致阻塞,如果能够异步地处理数据库读写请求的话,那么性能自然就上去了
同时也可以将redis引入,把判断秒杀库存和校验一人一单这种简单的逻辑缓存进redis,这样就不用让每一个请求都去查询数据库(因为是秒杀业务,优惠券信息不会太大,redis足以存储)
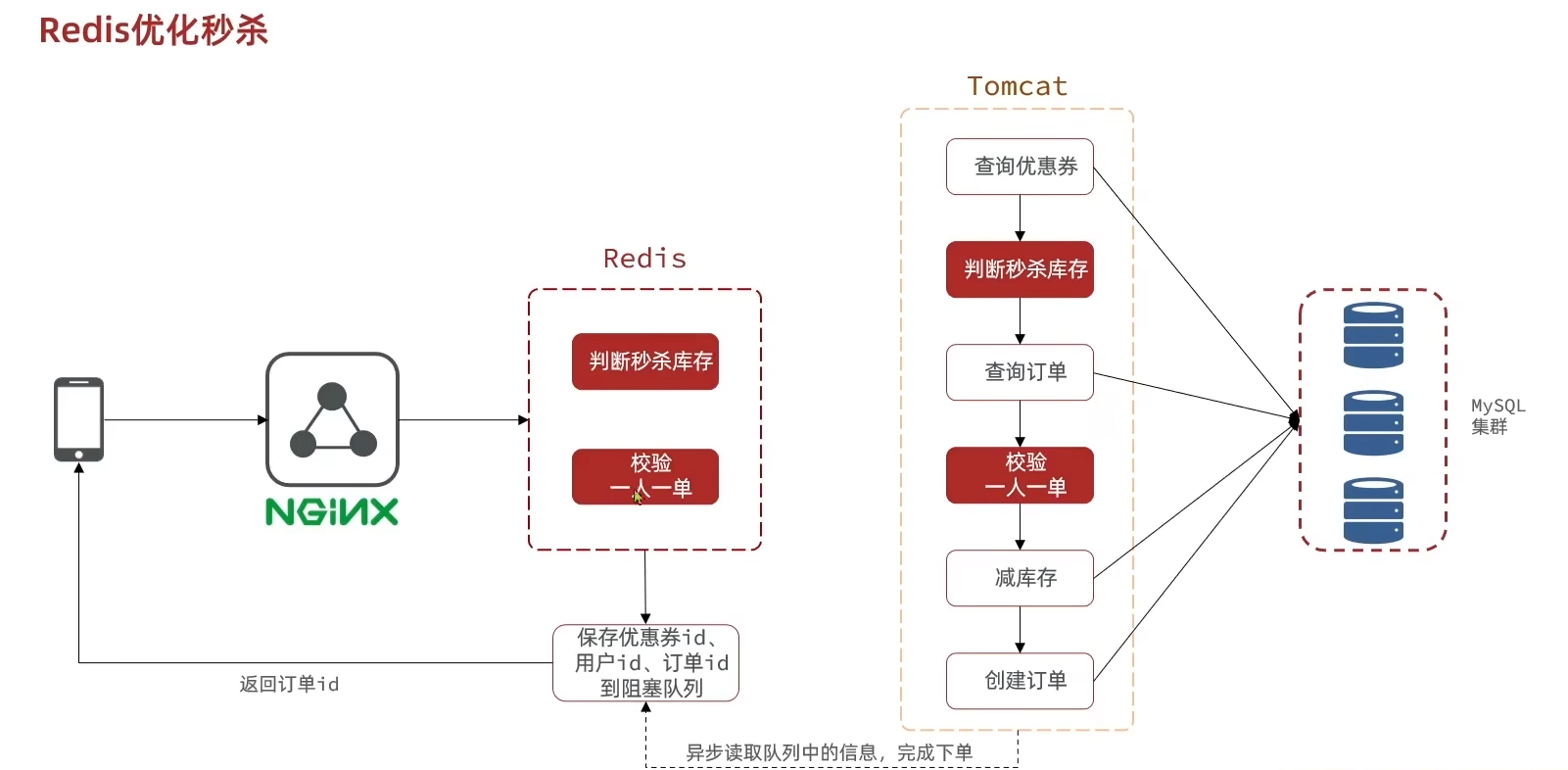
我们把库存和该用户是否购买过的信息存到redis里面,先用Lua脚本执行相关逻辑筛选一部分请求。筛选之后的请求异步对数据库进行操作,这样也就不会导致JVM阻塞了
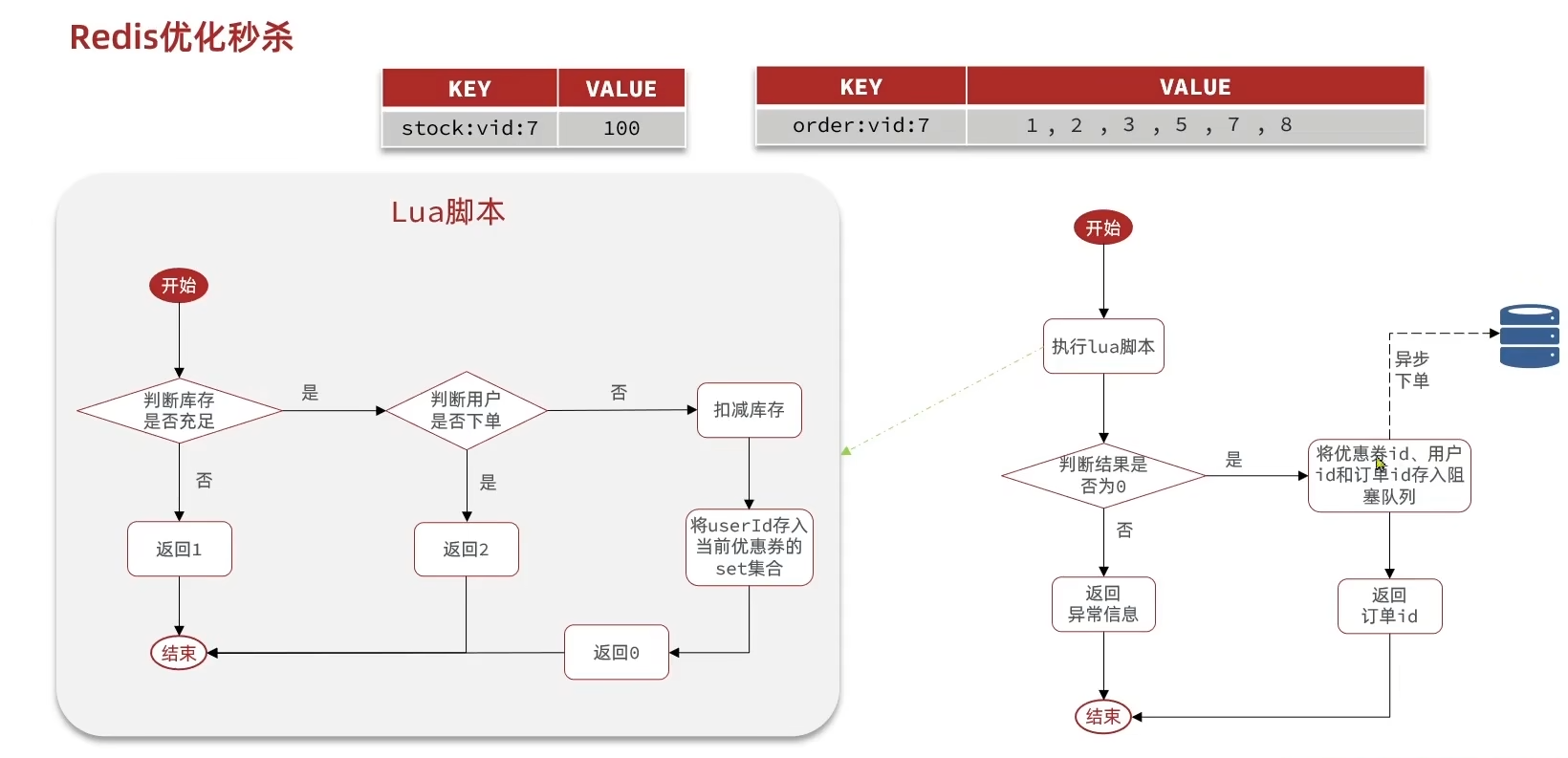
实现
把上面的流程图简化为需求如下:

只记一点不太清楚的地方
完成的Lua脚本如下:
-- 订单id
local voucherId = ARGV[1]
-- 用户id
local userId = ARGV[2]
-- 库存key
local stockKey = 'seckill:stock:' .. voucherId
-- 订单key
local orderKey = 'seckill:order:' .. voucherId
-- 判断库存是否充足
if(tonumber(redis.call('get',stockKey)) >= 0) then
-- 库存不足则返回1
return 1
end
-- 判断用户是否下过单
if (redis.call('sismember', orderKey, userId) == 1) then
-- 下过单则返回2
return 2
end
-- 扣库存和记录用户已下单
redis.call('incrby', stockKey, -1)
redis.call('sadd', orderKey, userId)
return 0回顾一下Lua脚本的两类参数KEYS和ARGV。在Redis里面Lua脚本是这样执行的:
EVAL script numkeys key1 key2 ... arg1 arg2 ...例子:
EVAL "return {KEYS[1],ARGV[1]}" 1 mykey helloRedis内部就会变成:
KEYS[1] = "mykey"
ARGV[1] = "hello"别的不用关心,在这段Lua脚本里面只出现了ARGV参数,之后在Java中调用的时候传入即可
这里最终完成的完整代码如下,东西有点多需要做一些说明:
package com.hmdp.service.impl;
import com.hmdp.dto.Result;
import com.hmdp.entity.SeckillVoucher;
import com.hmdp.entity.VoucherOrder;
import com.hmdp.mapper.VoucherOrderMapper;
import com.hmdp.service.ISeckillVoucherService;
import com.hmdp.service.IVoucherOrderService;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.hmdp.utils.RedisIdWorker;
import com.hmdp.utils.UserHolder;
import org.redisson.api.RLock;
import org.redisson.api.RedissonClient;
import org.springframework.aop.framework.AopContext;
import org.springframework.core.io.ClassPathResource;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.data.redis.core.script.DefaultRedisScript;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import javax.annotation.PostConstruct;
import javax.annotation.Resource;
import java.time.LocalDateTime;
import java.util.Collections;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* <p>
* 服务实现类
* </p>
*
* @author 虎哥
* @since 2021-12-22
*/
@Service
public class VoucherOrderServiceImpl extends ServiceImpl<VoucherOrderMapper, VoucherOrder> implements IVoucherOrderService {
@Resource
private ISeckillVoucherService seckillVoucherService;
@Resource
private RedisIdWorker redisIdWorker;
@Resource
private StringRedisTemplate stringRedisTemplate;
@Resource
private RedissonClient redissonClient;
// 用静态代码块初始化Lua脚本执行对象
private static final DefaultRedisScript<Long> SECKILL_SCRIPT;
static{
SECKILL_SCRIPT = new DefaultRedisScript<>();
SECKILL_SCRIPT.setLocation(new ClassPathResource("seckill.lua"));
SECKILL_SCRIPT.setResultType(Long.class);
}
// 新建阻塞队列、线程池和线程任务
private BlockingQueue<VoucherOrder> orderTasks = new ArrayBlockingQueue<>(1024 * 1024);
private static final ExecutorService seckill_order_executor = Executors.newSingleThreadExecutor();
@PostConstruct
private void init(){
seckill_order_executor.submit(new VoucherOrderHandler());
}
private class VoucherOrderHandler implements Runnable{
@Override
public void run(){
while(true){
try {
/*
获取阻塞队列中的订单信息
如果阻塞队列中没有元素,则会滞留在这里不会占用cpu运行
*/
VoucherOrder voucherOrder = orderTasks.take();
handleVoucherOrder(voucherOrder);
} catch (Exception e) {
log.error("处理订单异常",e);
}
}
}
}
// 异步下单的逻辑
private void handleVoucherOrder(VoucherOrder voucherOrder){
Long userId = voucherOrder.getUserId();
RLock lock = redissonClient.getLock("lock:order:" + userId);
boolean isLock = lock.tryLock();
if (!isLock){
log.error("不允许重复下单");
return;
}
try{
proxy.createVoucherOrder(voucherOrder);
} finally {
lock.unlock();
}
}
private IVoucherOrderService proxy;
/**
* 秒杀优惠券下单
* @param voucherId 传入的优惠券Id
* @return 统一响应格式,返回成功或失败原因
*/
@Override
public Result seckillVoucher(Long voucherId) {
// 从当前线程中获取用户Id
Long userId = UserHolder.getUser().getId();
// 执行lua脚本,这里因为没有KEYS参数,因此直接传一个空的emptyList
Long result = stringRedisTemplate.execute(
SECKILL_SCRIPT,
Collections.emptyList(),
voucherId.toString(),
userId.toString()
);
// result不为0则没有购买资格,应该判断原因并返回。为0则有购买资格
int r = result.intValue();
if (r != 0){
return Result.fail(r == 1 ? "库存不足" : "不能重复下单");
}
// 有购买资格则需要保存进入阻塞队列
VoucherOrder voucherOrder = new VoucherOrder();
long orderId = redisIdWorker.nextId("order");
voucherOrder.setId(orderId);
voucherOrder.setUserId(userId);
voucherOrder.setVoucherId(voucherId);
orderTasks.add(voucherOrder);
// 获取代理对象
proxy = (IVoucherOrderService) AopContext.currentProxy();
// 返回订单id
return Result.ok(orderId);
}
@Transactional
public void createVoucherOrder(VoucherOrder voucherOrder) {
Long userId = voucherOrder.getUserId();
// 判断该用户是否已经买过
int count = query().eq("user_id", userId).eq("voucher_id", voucherOrder.getVoucherId()).count();
if (count > 0) {
log.error("用户已购买过一次!");
return;
}
// 先让库存数减一
boolean success = seckillVoucherService.update()
.setSql("stock = stock - 1")
.eq("voucher_id", voucherOrder.getVoucherId()).gt("stock", 0).update();
if (!success) {
// 扣减库存失败,一般认为也是库存不足
log.error("库存不足");
return;
}
save(voucherOrder);
}
}这里的说明仅针对于当下情况的代码,不考虑后面用的Stream和MQ等
- 这里总共只有两个线程,主线程负责处理Controller层传来的请求,子线程负责完成下单写数据库
orderTasks是 类成员变量,而不是线程变量,因此所有线程共享同一个队列- 由于线程池里面只有一个线程,因此子线程相关的代码是严格串行执行
proxy代理对象的获取是依据于AopContext.currentProxy()的,本质是对象引用。因此子线程要调用的话,必须先在主线程获取
在这里RLock锁其实已经不工作了,可以举个例子来分析一下:
考虑极限情况,A用户传来两个订单1 2,它们都通过了lua脚本校验进入了阻塞队列中,但由于是单线程,只能先取一个处理完成之后再取第二个,也就是说,1先进handleVoucherOrder下单成功(此时2还在队列里面阻塞,不可能出来跟它抢订单,况且这里仅仅是单线程,也不可能同时处理两个订单),然后2再出来,此时1已经处理完了,最后释放锁,2在这里依然能拿到锁,但是因为
createVoucherOrder里面有针对于数据库的SQL校验,因此还是没问题的,只是性能依然不高(毕竟要查数据库)
但这里仍然把RLock作保留,因为如果是真实生产环境肯定不可能用单线程池,在多线程池的情况下锁依然和以前一样发挥作用
秒杀优化的优化
在上面用的阻塞队列是由Java提供的,也就是说存进阻塞队列的所有数据都是存在JVM内存中的,那么这里就会存在两点问题:
- 空间不足导致消息无法存入,订单丢失
- 若JVM抛异常崩溃,则数据安全无法保证(进入阻塞队列的元素直接丢失)
所以在这里应该将阻塞队列替换为消息队列
消息队列更类似于”快递柜“的一种中间媒介,它不仅仅是”保存“数据,更起到”管理“数据的作用,模型如下:

消息队列有更专业的如Rocket MQ、kafka等实现,这里简要学习就先用Redis来做
Redis有三种方式来实现消息队列,前面两种这里看看就行不用太在意,这里主要看Stream方式,其数据结构如下所示:
ID fields
------------------------------------
1710000000000-0 userId=12 orderId=88
1710000001000-0 userId=15 orderId=90
1710000002000-0 userId=20 orderId=91每条消息都为ID + key-value字段,ID结构为时间戳-序号,由redis自动生成,也可以自己写但没必要
发送、读取消息以及一个缺点如下:


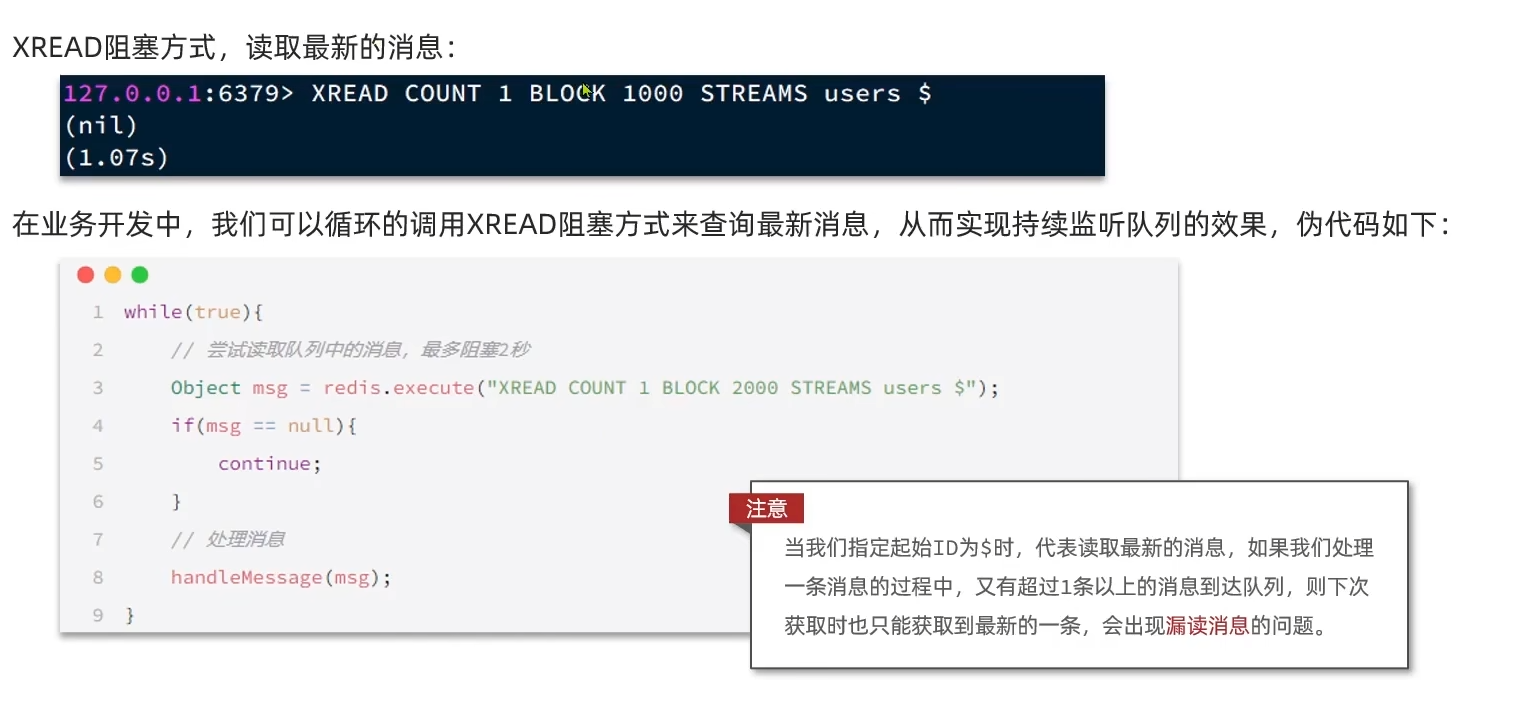

效果不错,但现在要解决消息漏读的那个缺点,这里引入消费者组的概念,其特点如下:

相关操作命令如下:

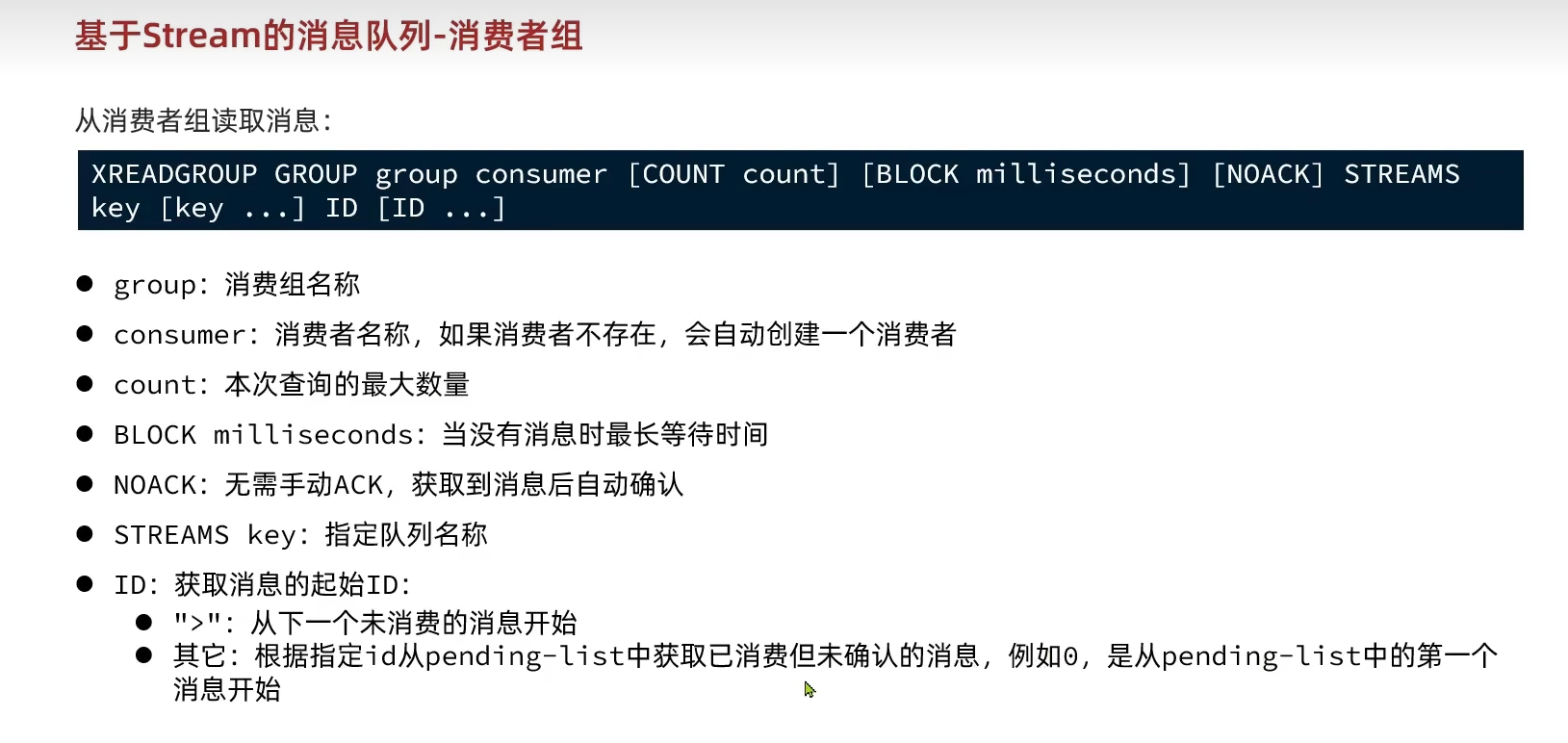
到这里为止的命令参数有点多也有点复杂,举几个例子方便理解和辨析
- 执行
XREAD COUNT 1 STREAMS stream1 0的意思是读取 ID > 0 的消息,而不是ID = 0,这里认为诸如1773495244097-0等ID都是>0、1等的 XRANGE stream1 - + COUNT count可以查看一个key里面的前count个消息xgroup create stream1 order1 0:创建一个名为order1的消费者组专门处理名为stream1的消息队列,消费起点为0xreadgroup GROUP order1 csume1 COUNT 1 STREAMS stream1 0,这里的0表示从当前消费者的PEL(pending list)读取消息,而不是从ID = 0开始读。xreadgroup GROUP order1 csume1 COUNT 1 STREAMS stream1 >,这里的>表示读取 “从未分配给任何消费者” 的新消息
看这个例子,给各个关键行为都弄清楚:
127.0.0.1:6379> XRANGE stream1 - +
1) 1) "1773495244097-0"
2) 1) "s1"
2) "k1"
2) 1) "1773495829922-0"
2) 1) "s2"
2) "k2"
3) 1) "1773500045510-0"
2) 1) "s2"
2) "k2"
127.0.0.1:6379> xgroup create stream1 order1 0
OK
127.0.0.1:6379> xreadgroup GROUP order1 csume1 COUNT 1 STREAMS stream1 0
1) 1) "stream1"
2) (empty array)
127.0.0.1:6379> xreadgroup GROUP order1 csume1 COUNT 1 STREAMS stream1 >
1) 1) "stream1"
2) 1) 1) "1773495244097-0"
2) 1) "s1"
2) "k1"
127.0.0.1:6379> xreadgroup GROUP order1 csume2 COUNT 1 STREAMS stream1 >
1) 1) "stream1"
2) 1) 1) "1773495829922-0"
2) 1) "s2"
2) "k2"
127.0.0.1:6379> xreadgroup GROUP order1 csume3 COUNT 1 STREAMS stream1 >
1) 1) "stream1"
2) 1) 1) "1773500045510-0"
2) 1) "s2"
2) "k2"
127.0.0.1:6379> xreadgroup GROUP order1 csume4 COUNT 1 STREAMS stream1 >
(nil)
127.0.0.1:6379> xreadgroup GROUP order1 csume1 COUNT 1 STREAMS stream1 0
1) 1) "stream1"
2) 1) 1) "1773495244097-0"
2) 1) "s1"
2) "k1"
127.0.0.1:6379> xreadgroup GROUP order1 csume1 COUNT 1 STREAMS stream1 1
1) 1) "stream1"
2) 1) 1) "1773495244097-0"
2) 1) "s1"
2) "k1"
127.0.0.1:6379> xreadgroup GROUP order1 csume1 COUNT 1 STREAMS stream1 $
(error) ERR The $ ID is meaningless in the context of XREADGROUP: you want to read the history of this consumer by specifying a proper ID, or use the > ID to get new messages. The $ ID would just return an empty result set.
127.0.0.1:6379> xreadgroup GROUP order1 csume1 COUNT 1 STREAMS stream1 1773495244097-0
1) 1) "stream1"
2) (empty array)
127.0.0.1:6379> xreadgroup GROUP order1 csume1 COUNT 1 STREAMS stream1 0
1) 1) "stream1"
2) 1) 1) "1773495244097-0"
2) 1) "s1"
2) "k1"
127.0.0.1:6379> XPENDING stream1 order1
1) (integer) 3
2) "1773495244097-0"
3) "1773500045510-0"
4) 1) 1) "csume1"
2) "1"
2) 1) "csume2"
2) "1"
3) 1) "csume3"
2) "1"
127.0.0.1:6379> xreadgroup GROUP order1 csume1 COUNT 1 STREAMS stream1 1773495244097-0
1) 1) "stream1"
2) (empty array)第一次读取xreadgroup GROUP order1 csume1 COUNT 1 STREAMS stream1 0,返回(empty array)
原因是在 XREADGROUP 里,0 表示:读取当前消费者的 pending 消息。但是csume1 还没有 pending,所以返回空
后面xreadgroup GROUP order1 csume COUNT 1 STREAMS stream1 >依次分配三个消息,分配完之后csume4读取到nil表示消息以及分配完毕
然后再xreadgroup GROUP order1 csume1 STREAMS stream1 0,此时返回M1,因为当前0 = 读取当前消费者的 pending,同时在读取 PEL 时规则是返回 ID > 指定ID 的 pending,因此ID = 1也会获取相同结果
一点碎碎念:
这里的“消费者组”其实真正重要的并不是“一堆消费者组在一起处理消息”(实际上大部分项目的消费者组也就只有一个消费者),而是一套独立的消费状态与可靠消费机制,group的本质也就是一套独立的消费状态。用
消费进度 last-delivered-id表示这个 group 已经发到哪条消息、用未确认消息 PEL表示哪些消息以及发出但没有ACK。其实更应该翻译成类似于消费状态组之类的东西,但因为历史遗留之类的原因还叫消费者组

然后改一下代码,主要得修改之前的seckiil.lua和VoucherOrderServiceImpl里面的处理,这里只记录一些测试的过程以及一些注意事项
-
消息队列应该提前在redis里面创建好,若redis里面未创建
stream.orders这个key则运行会直接报错 -
登录获取token,然后用postman模拟购买优惠券,可以发现限购、redis缓存等都可以正常运行:
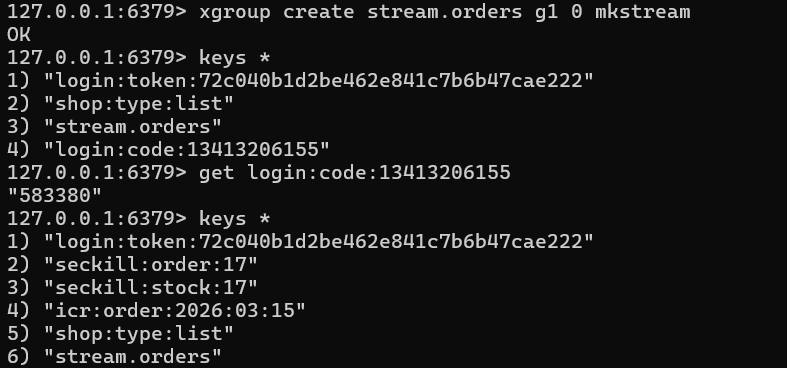
用测试代码模拟99个不同用户来下单:
@Test
public void testSeckill_100() throws InterruptedException {
int threadCount = 99;
CountDownLatch latch = new CountDownLatch(threadCount);
Long voucherId = 17L;
AtomicInteger successCount = new AtomicInteger();
AtomicInteger failCount = new AtomicInteger();
for (int i = 0; i < threadCount; i++) {
final long userId = i + 1; // 每个线程一个不同用户
executor.submit(() -> {
try {
UserDTO user = new UserDTO();
user.setId(userId);
UserHolder.saveUser(user);
Result result = voucherOrderService.seckillVoucher(voucherId);
if (result.getSuccess()) {
successCount.incrementAndGet();
} else {
failCount.incrementAndGet();
}
System.out.println("用户 " + userId + " 下单结果: " + result);
} catch (Throwable e) {
e.printStackTrace();
} finally {
latch.countDown();
}
});
}
latch.await();
Thread.sleep(3000);
System.out.println("测试完成,成功:" + successCount.get() + ",失败:" + failCount.get());
}均成功,而且效率不赖,此时库存为0,然后再次发送测试请求,可以发现均下单失败,原因为库存不足
把库存再加到100,现在测试1000个用户(包括上面测试过的99个),再来看看结果:
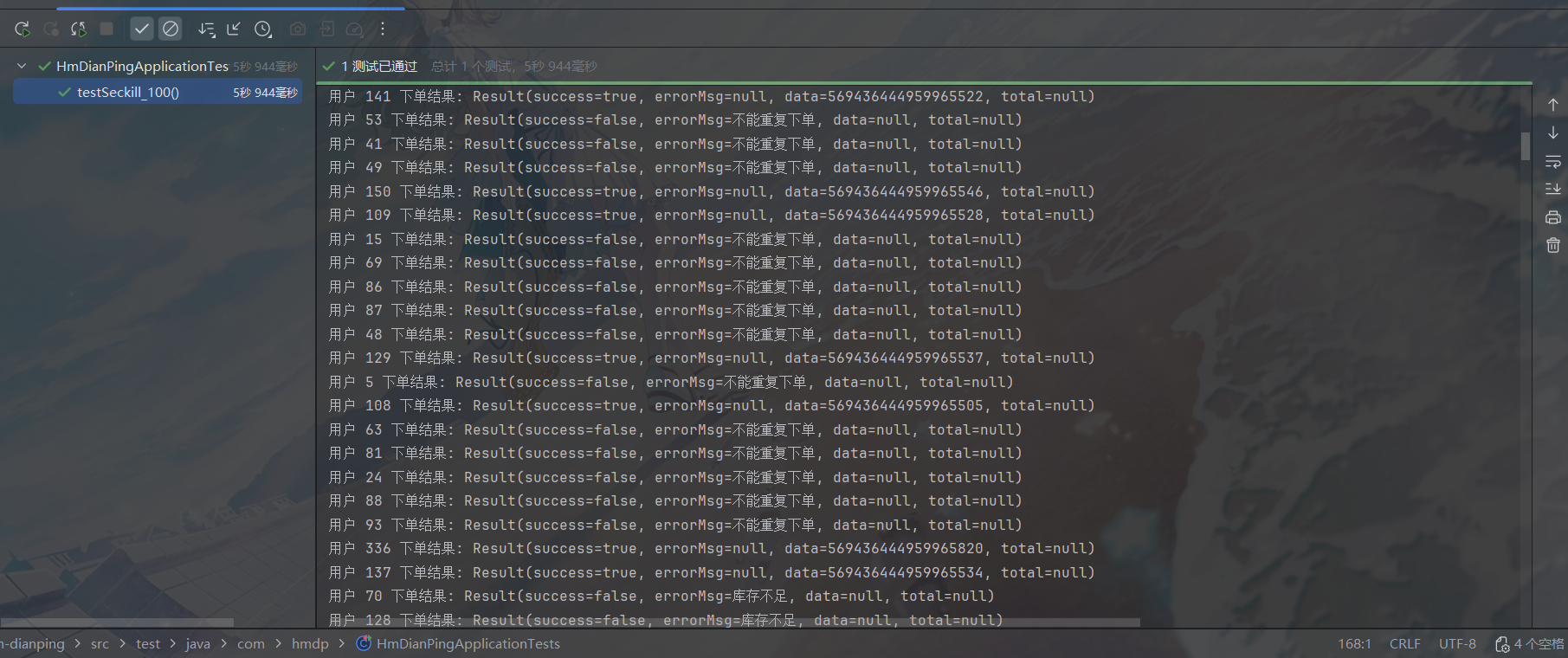
有的成功有的失败,失败原因也符合预期,这里就认为可以了吧。现在再来测一下PEL能不能处理异常消息,往消费代码的handleVoucherOrder(voucherOrder);后面加一行:
if(true) throw new RuntimeException();这里的逻辑是模拟下单成功之后还未确认消息已处理就抛异常,我想看看这段代码能不能符合预期,即既能保证用户不会多次购买,处理完成的消息也能及时得到确认防止PEL堆积
把上面的测试代码改成50个线程测试看看:
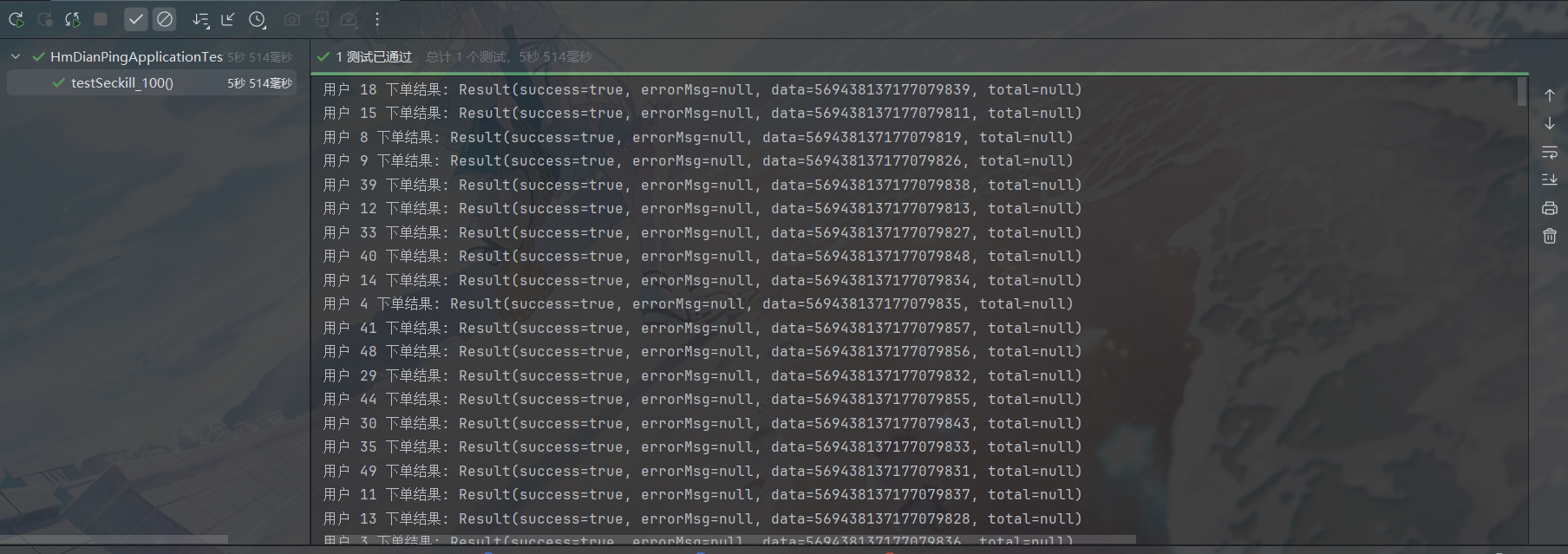
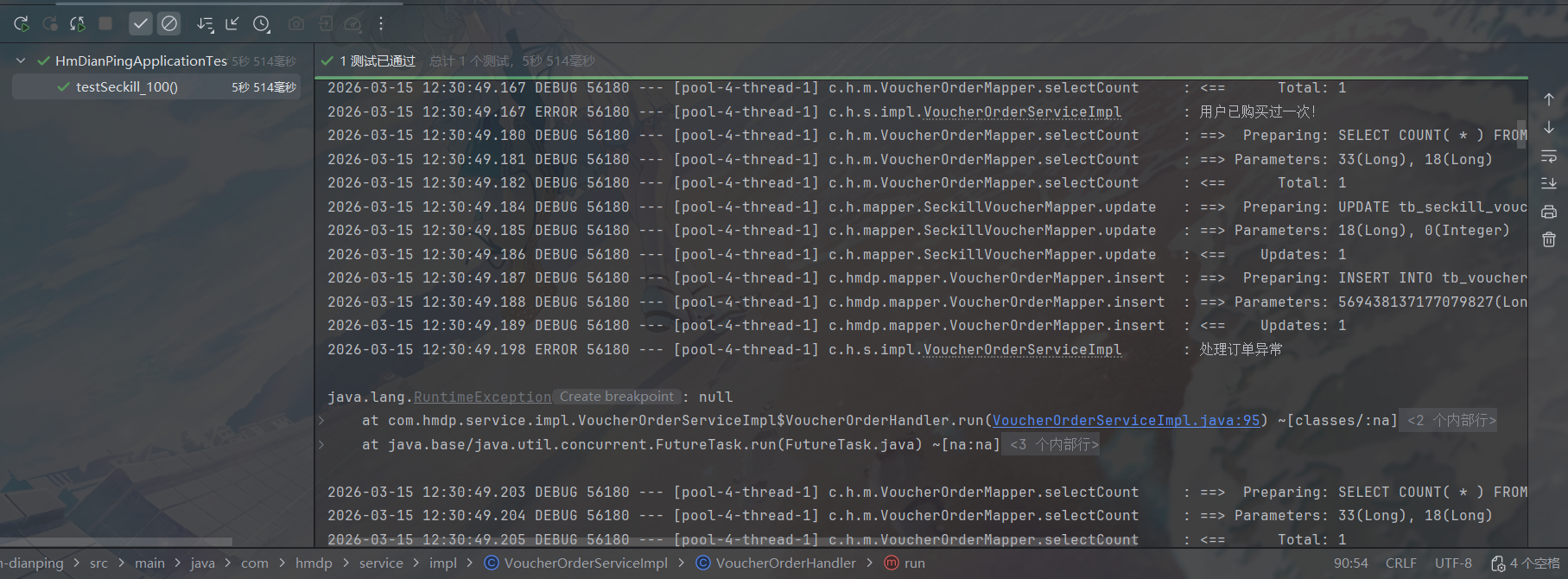
看起来好像没啥问题了,如果上了多线程异步多消费者处理的话可能会更麻烦一点,但现在秒杀相关就到这里为止
停止运行程序的时候发现会报错(在运行的时候不影响使用),是从这里抛出来的:
private static final ExecutorService seckill_order_executor = Executors.newSingleThreadExecutor();
@PostConstruct
private void init(){
seckill_order_executor.submit(new VoucherOrderHandler());
}
private class VoucherOrderHandler implements Runnable{
private final String queueName = "stream.orders";
@Override
public void run(){
while(true){
try {
/*
获取消息队列中的订单信息
如果获取失败则继续循环读取
如果获取成功则可以准备下单
*/
List<MapRecord<String, Object, Object>> list = stringRedisTemplate.opsForStream().read(
Consumer.from("g1", "c1"),
StreamReadOptions.empty().count(1).block(Duration.ofSeconds(2)),
StreamOffset.create(queueName, ReadOffset.lastConsumed())
);
if (list == null || list.isEmpty()){
continue;
}
// 解析消息中的订单信息
MapRecord<String, Object, Object> record = list.get(0);
Map<Object, Object> values = record.getValue();
VoucherOrder voucherOrder = BeanUtil.fillBeanWithMap(values, new VoucherOrder(), true);
handleVoucherOrder(voucherOrder);
// 完成后需要ACK确认消息已经被处理
stringRedisTemplate.opsForStream().acknowledge(queueName,"g1",record.getId());
} catch (Exception e) {
log.error("处理订单异常",e);
// 如果处理消息的时候抛了异常,消息也就没有被成功ACK,需要从PEL里面再取出并处理
handlePendingList();
}
}
}这里另起了一个线程无限循环读取redis消息队列中的数据
当springboot关闭的时候顺序执行:
- 关闭 RedisConnectionFactory
- 销毁 Lettuce 客户端
- 关闭 Netty 线程池
- 清理连接池
当停止redis连接的时候这个线程依然在跑,先报错连接失败。之后Netty线程池被关闭的时候就直接被强制终止了
根本原因就是spring不知道我这个线程池(因为是我自己new的)
改成这样就行:
private static final ExecutorService seckill_order_executor = Executors.newSingleThreadExecutor();
private VoucherOrderHandler handler;
private volatile boolean running = true;
@PostConstruct
private void init(){
handler = new VoucherOrderHandler();
seckill_order_executor.submit(handler);
}
@PreDestroy
public void destroy() {
running = false;
seckill_order_executor.shutdown();
}
private class VoucherOrderHandler implements Runnable{
private final String queueName = "stream.orders";
@Override
public void run(){
while(running && !Thread.currentThread().isInterrupted()){
try {
/*
获取消息队列中的订单信息
如果获取失败则继续循环读取
如果获取成功则可以准备下单
*/
List<MapRecord<String, Object, Object>> list = stringRedisTemplate.opsForStream().read(
Consumer.from("g1", "c1"),
StreamReadOptions.empty().count(1).block(Duration.ofSeconds(2)),
StreamOffset.create(queueName, ReadOffset.lastConsumed())
);
if (list == null || list.isEmpty()){
continue;
}
// 解析消息中的订单信息
MapRecord<String, Object, Object> record = list.get(0);
Map<Object, Object> values = record.getValue();
VoucherOrder voucherOrder = BeanUtil.fillBeanWithMap(values, new VoucherOrder(), true);
handleVoucherOrder(voucherOrder);
// 完成后需要ACK确认消息已经被处理
stringRedisTemplate.opsForStream().acknowledge(queueName,"g1",record.getId());
} catch (Exception e) {
// 如果是应用正在关闭,就直接退出
if (!running || Thread.currentThread().isInterrupted()) {
break;
}
log.error("处理订单异常",e);
// 如果处理消息的时候抛了异常,消息也就没有被成功ACK,需要从PEL里面再取出并处理
handlePendingList();
}
}
}
private void handlePendingList() {
while(running && !Thread.currentThread().isInterrupted()){
try {
/*
获取PEL中的订单信息
如果获取失败则继续循环读取
如果获取成功则可以准备下单
*/
List<MapRecord<String, Object, Object>> list = stringRedisTemplate.opsForStream().read(
Consumer.from("g1", "c1"),
StreamReadOptions.empty().count(1),
StreamOffset.create(queueName, ReadOffset.from("0"))
);
if (list == null || list.isEmpty()){
// 如果获取失败,则说明PEL里面没有异常消息,直接结束即可
break;
}
// 解析消息中的订单信息
MapRecord<String, Object, Object> record = list.get(0);
Map<Object, Object> values = record.getValue();
VoucherOrder voucherOrder = BeanUtil.fillBeanWithMap(values, new VoucherOrder(), true);
handleVoucherOrder(voucherOrder);
// 完成后需要ACK确认消息已经被处理
stringRedisTemplate.opsForStream().acknowledge(queueName,"g1",record.getId());
} catch (Exception e) {
if (!running || Thread.currentThread().isInterrupted()) {
return;
}
log.error("处理订单异常",e);
}
}
}
}主要就是加了一个生命周期注解方法和running标识来手动停止那个线程就行
@PreDestroy
public void destroy() {
running = false;
seckill_order_executor.shutdown();
}这个@PreDestroy 是 JSR-250 提供的生命周期注解,用于标记“Bean 被销毁前要执行的方法。对于被 Spring 管理的 Bean(比如 VoucherOrderServiceImpl),当应用关闭、Spring 容器销毁这个 Bean 时,就会自动调用这个方法
达人谈店
在博客点赞这里,需要展示前五个为博客点赞的用户,一开始直接用mp提供的listById来查询,相关SQL语句为:
SELECT id,phone,password,nick_name,icon,create_time,update_time FROM tb_user WHERE id IN ( ? , ? )然而这里发现了一个bug:后端代码传入的顺序没有问题,但实际展示却是后点赞的在前面
原因是SQL 的 IN 查询结果默认是“无序的”,没法保证哪个在前哪个在后,顺序取决于执行计划 / 索引 / 存储结构等
也就是说,假设查id = 1和id = 5的两个用户数据,一般都是id = 1那个在前,因为user数据库以id作为主键
因此这里的SQL应该改成类似于这样的:
SELECT *
FROM tb_user
WHERE id IN (5,1)
ORDER BY FIELD(id, 5,1)Java里面的mp写法:
String idStr = StrUtil.join(",",ids);
// 根据得到的用户id查询用户并转换为userDTO类型
List<UserDTO> userDTOS = userService.query()
.in("id",ids).last("ORDER BY FIELD(id," + idStr + ")").list()
.stream()
.map(user -> BeanUtil.copyProperties(user, UserDTO.class))
.collect(Collectors.toList());好友关注
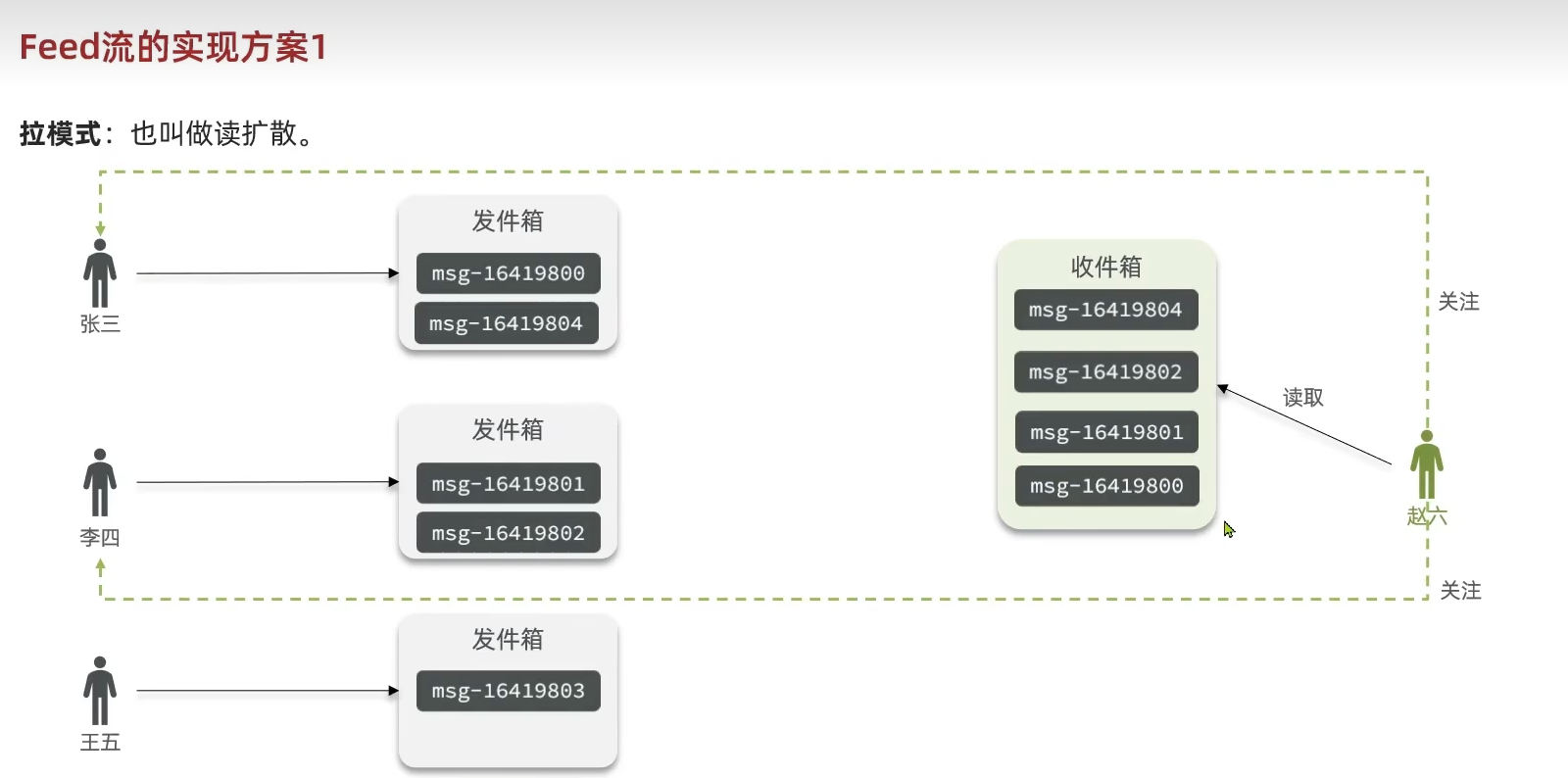
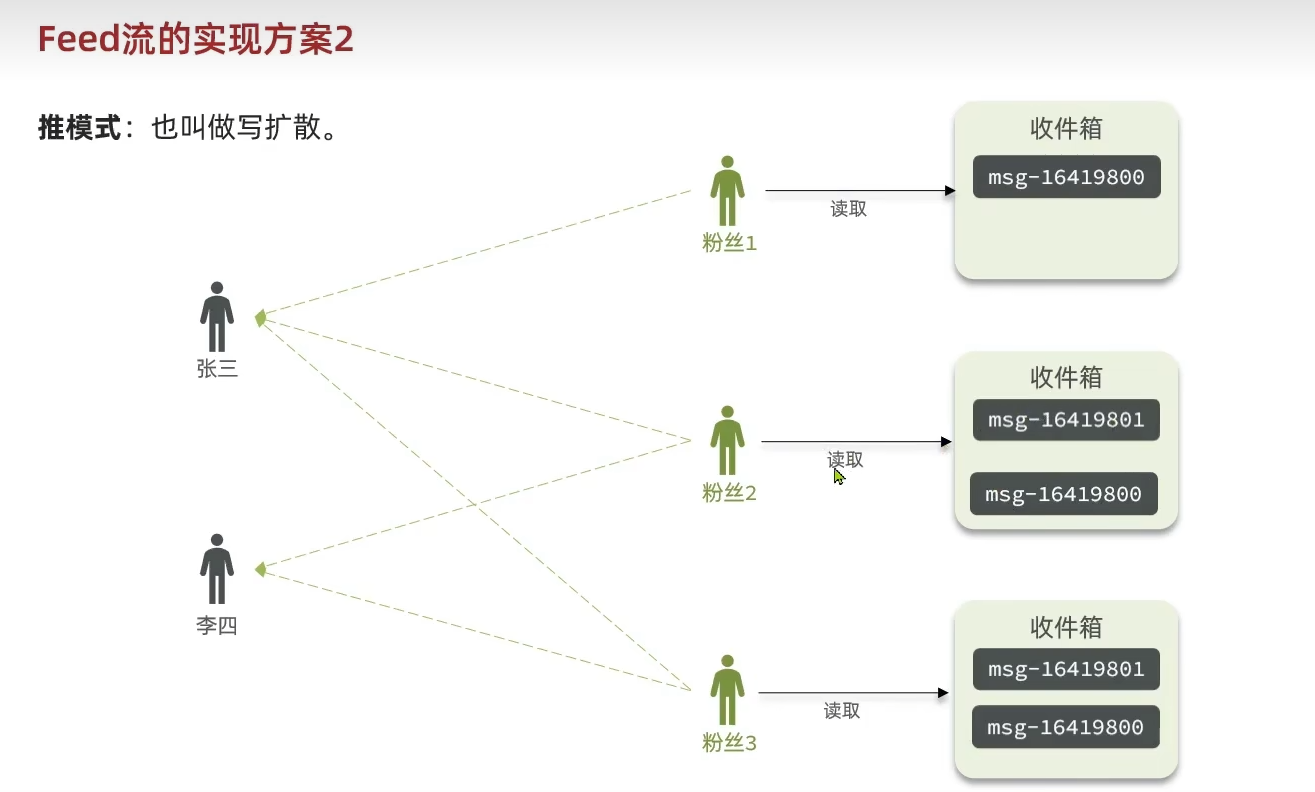
Feed流有三种实现方案:
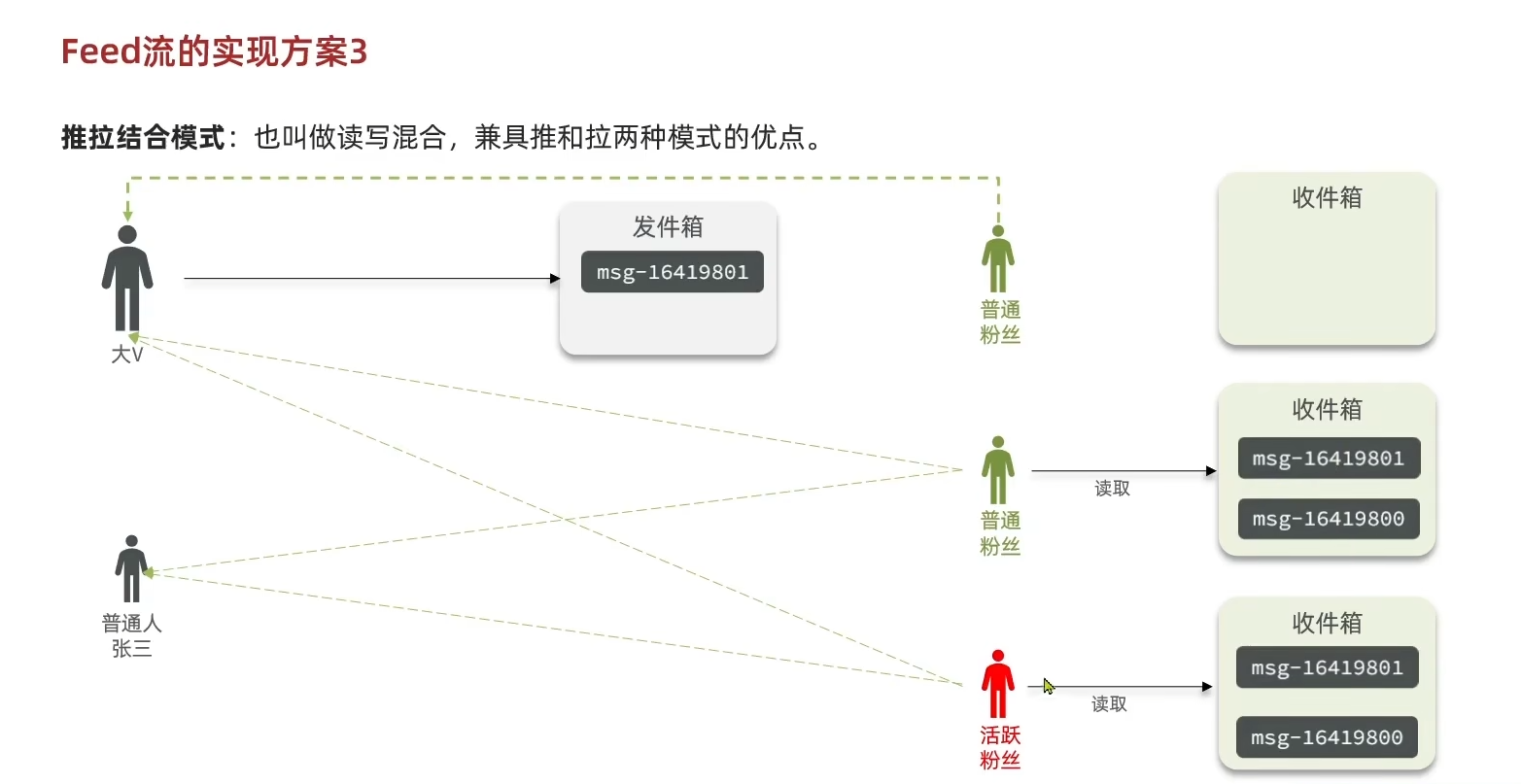
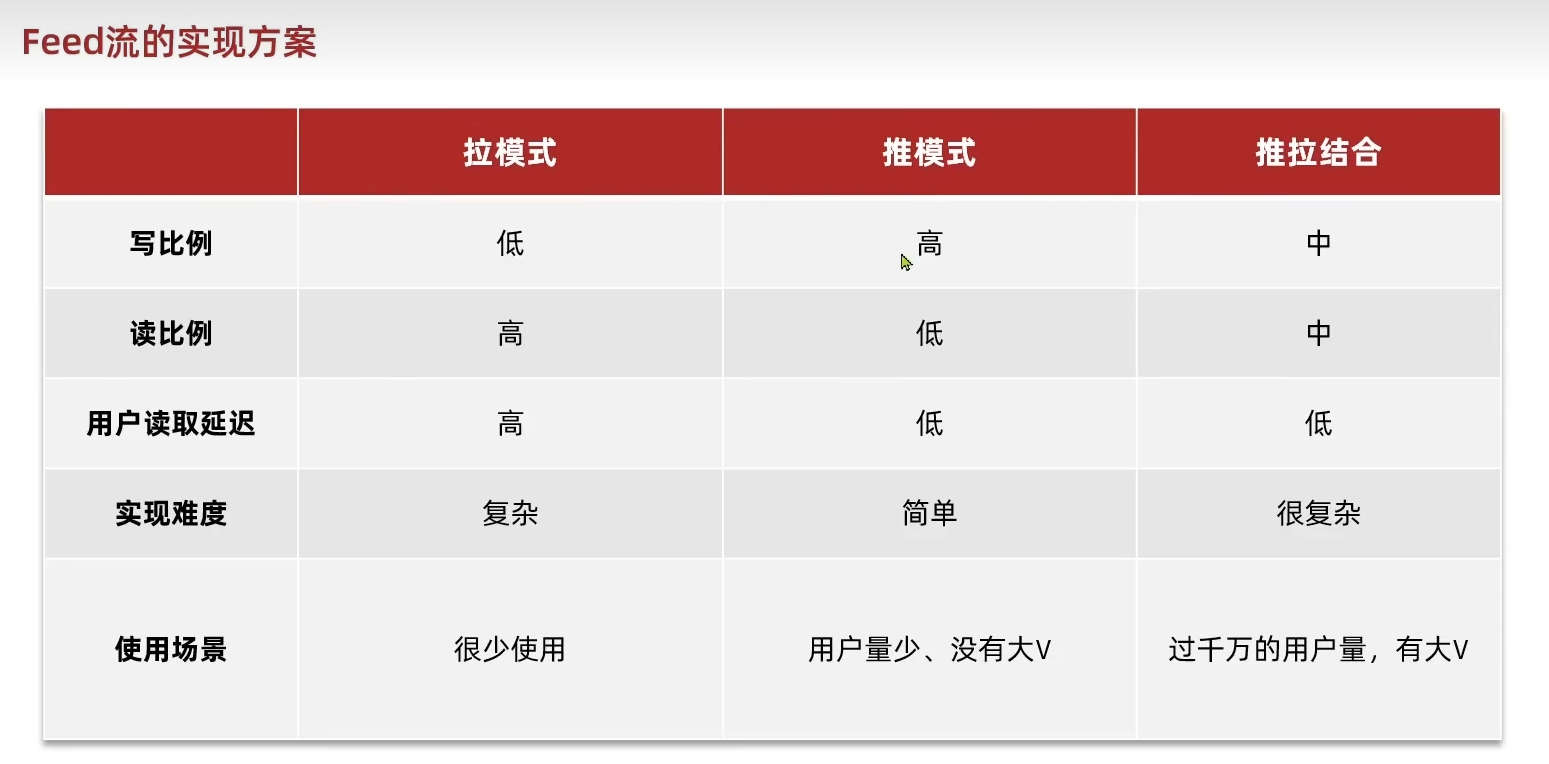
这个点评项目也没什么用户量~~(其实根本没有)~~,写个简单的推模式得了,需求如下:

这里涉及的问题主要有:
- 作为收件箱的Redis选取怎样的数据结构(
List和sortedset都可以排序) - 收件箱如何做到分页查询
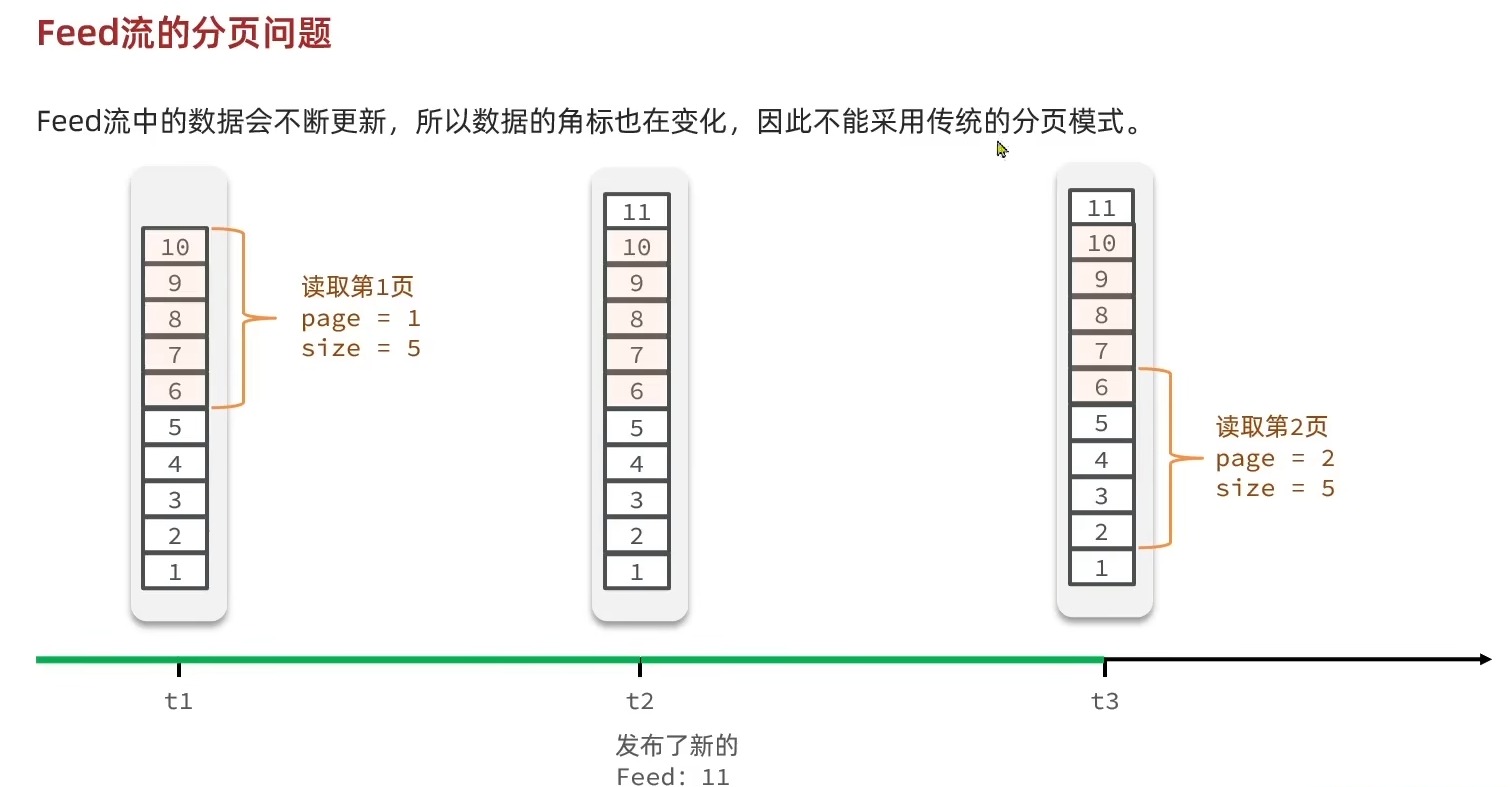
根据这里的分析,Redis的数据结构应该选sortedset,每当有人发布新的笔记时就将其存到Redis中
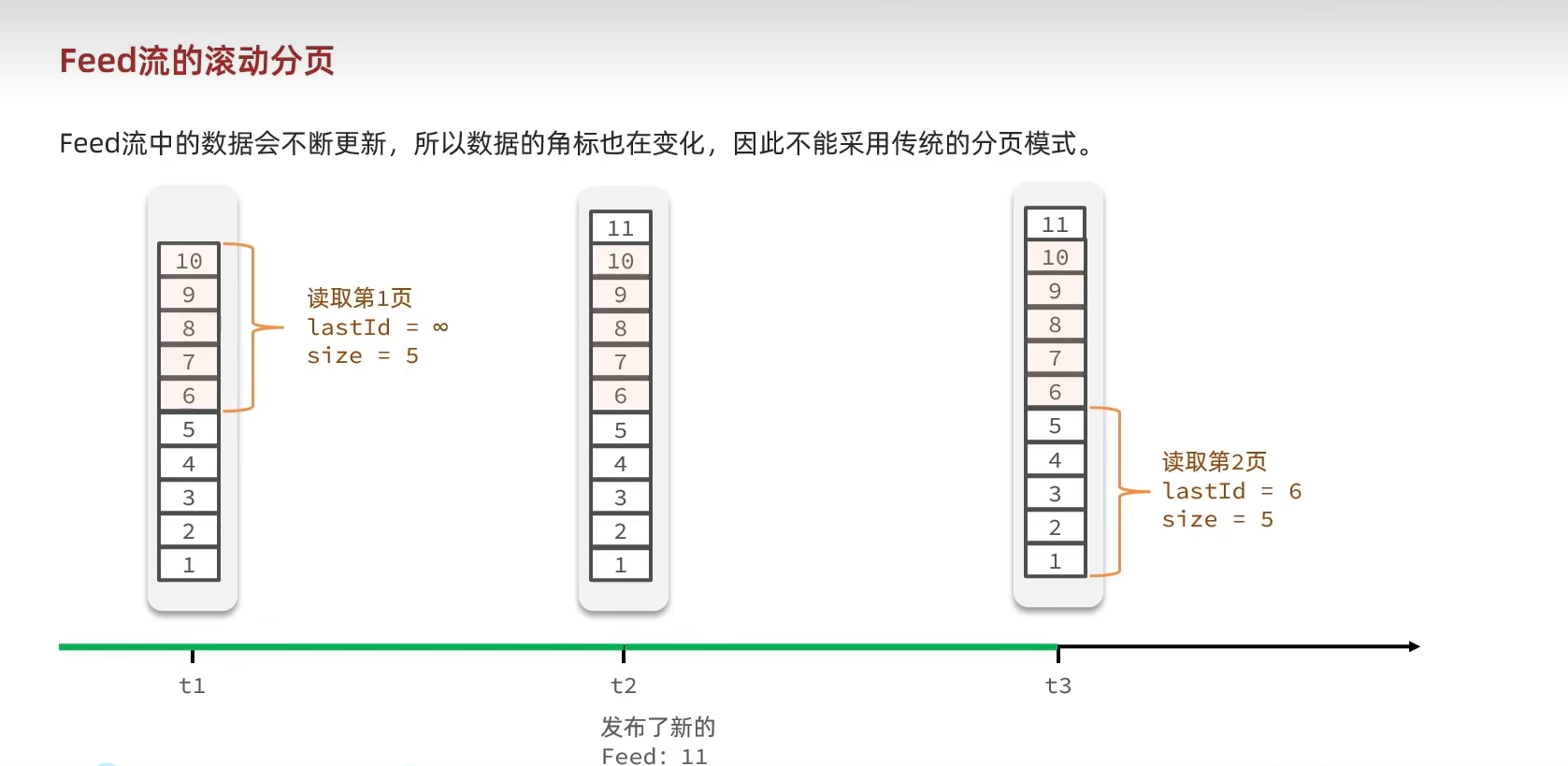
滚动查询实现
相关参数如下:
max:当前时间戳(第一页) | 上一次查询的最小时间戳(后面所有页)
min:0(最小时间戳)
offset:0(第一页) | 上一次查询的最小时间戳一致的所有元素个数(后面所有页,需要跳过的元素个数)
count:分页大小(这里为3)相关需求:
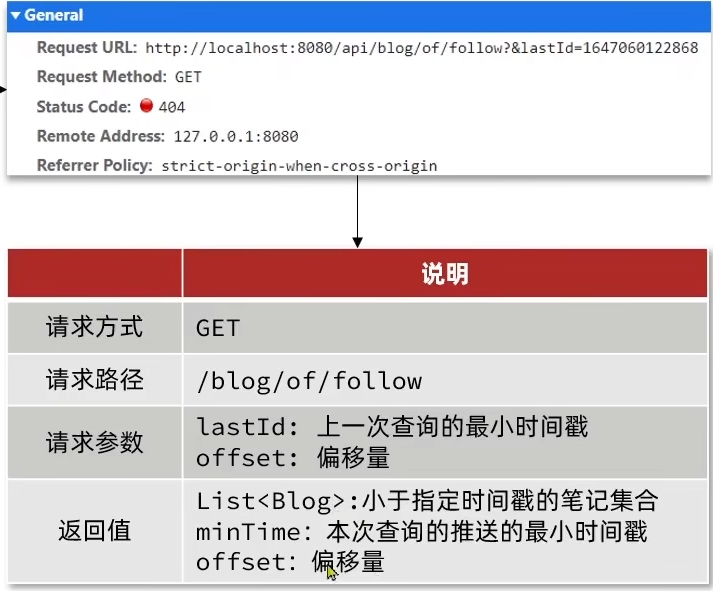
感觉没什么好记的,直接过吧
附近商户
GEO数据结构

业务需求:
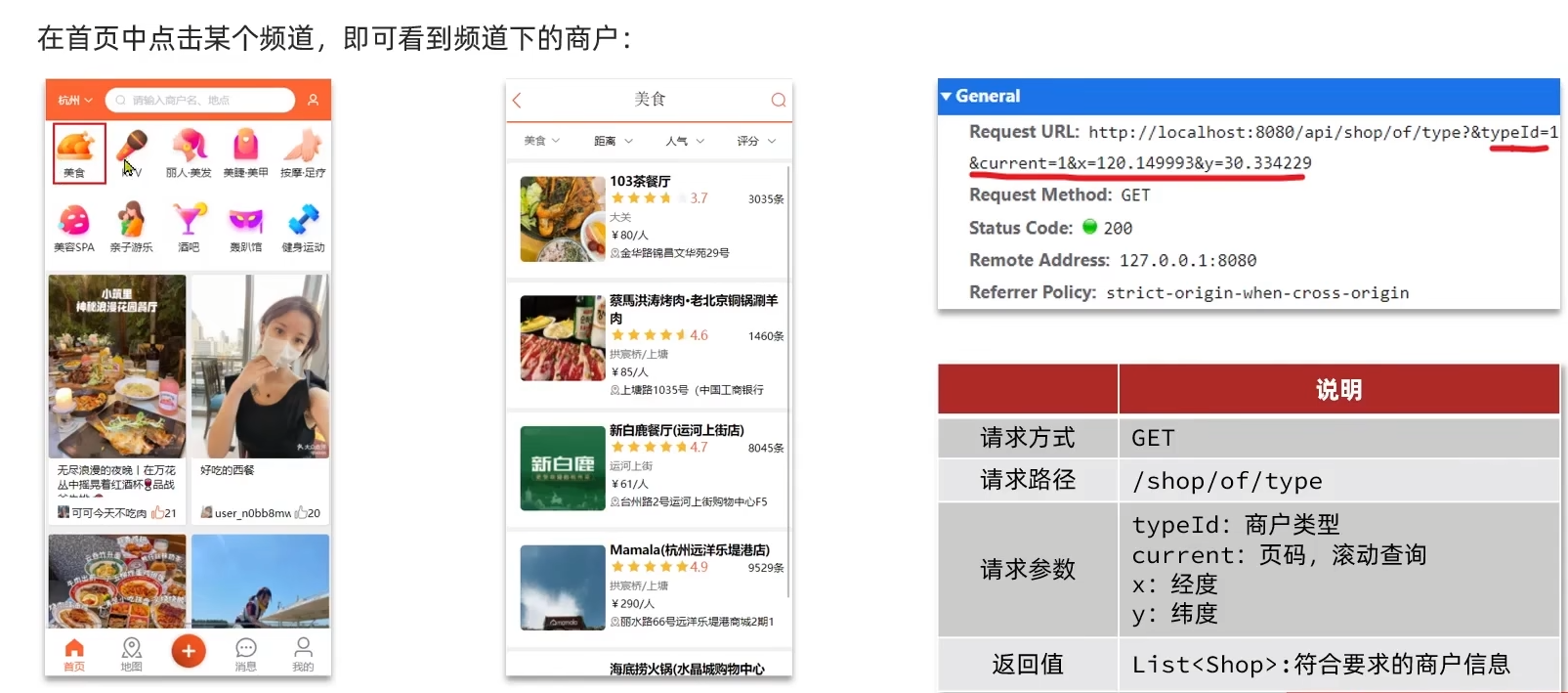
写个测试方法(方便运行),把数据库中的商户数据添加到redis的GEO数据结构中
@Test
public void loadShopGeoData(){
List<Shop> shopList = shopService.list();
// 按照商户的类型Id分组,比如美食类一组、ktv类一组等
Map<Long, List<Shop>> map = shopList.stream().collect(Collectors.groupingBy(Shop::getTypeId));
// 分组完后分批写入Redis
for (Map.Entry<Long, List<Shop>> entry : map.entrySet()){
// 按照类型Id分组
Long typeId = entry.getKey();
String Key = "shop:geo:" + typeId;
List<Shop> shopValue = entry.getValue();
// 该list为Geo数据类型list
List<RedisGeoCommands.GeoLocation<String>> locations = new ArrayList<>(shopValue.size());
// 先写入locations,然后再统一写入Redis提升效率
for (Shop shop : shopValue){
locations.add(new RedisGeoCommands.GeoLocation<>(
shop.getId().toString(),
new Point(shop.getX(),shop.getY())
));
}
stringRedisTemplate.opsForGeo().add(Key,locations);
}
}每日签到
签到这里我觉得主要有一个对BitMap用法以及其解决这类问题的相关思路就行




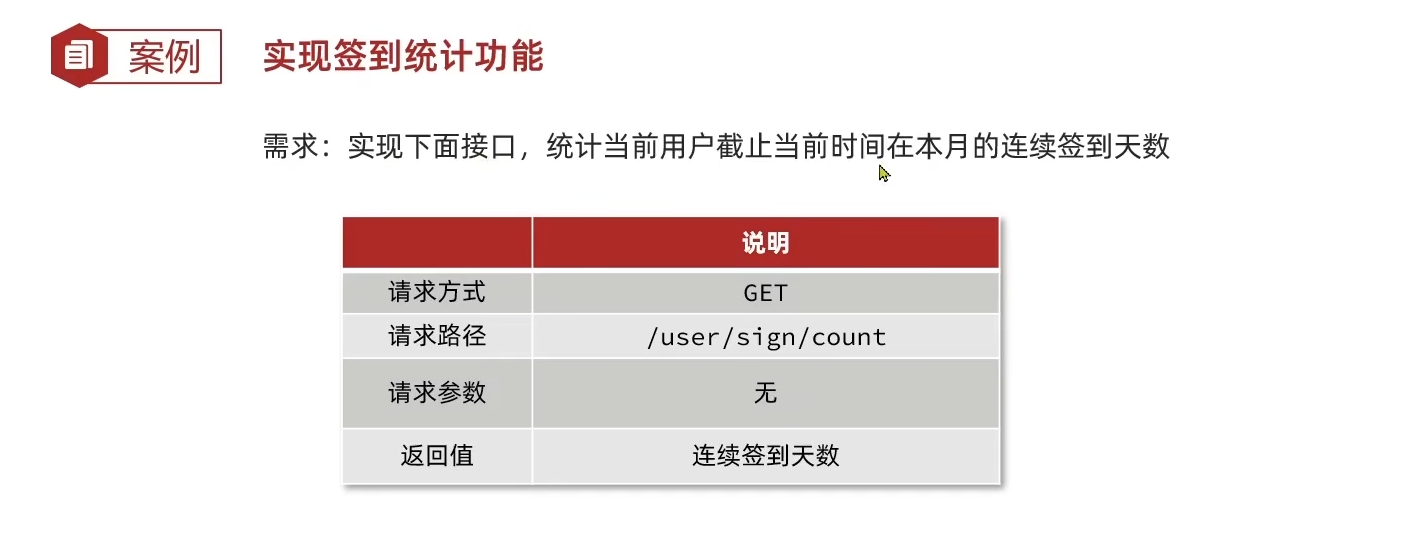
至于相关代码就不写了,前端也没有相应的签到功能,就这样吧,跟随视频敲的就到此为止,下面是一些自己后续的修改和回顾