很难想象有人读了一年计算机现在才开始学 git 相关操作.....
其实之前也一直在用,但每次都是用的时候搜和问 AI,也就是下点东西用。没怎么梳理过相关知识,github 的页面自己也不太熟悉,更别提什么仓库管理、合并分支之类的
学习视频:https://www.bilibili.com/video/BV1pX4y1S7Dq
# 安装 Git
这里不赘述了,之前装过
# 创建本地仓库
随便在本地找一个文件夹,在这个目录的 cmd 窗口下输入:
1 | git init |
此时这个文件夹就成为了自己本地的 git 仓库(不需要联网)
同时也可以用:
1 | git clone URL |
来克隆 github 上面别人的仓库
# Git 文件状态
# 基本文件状态以及对应操作
仓库里面的文件有四种状态,分别是:未跟踪、未修改、已修改、暂存
初始仓库里的文件都是未跟踪的,可以用
1 | git add <name> |
来让某个文件或者目录变为暂存状态,也可以理解为让 git 跟踪它
然后可以用
1 | git rm <name> |
来取消对某个文件的跟踪(但这会直接把它删掉)
如果不想删掉这个文件,只是取消跟踪,可以用
1 | git rm --cached <name> |
修改已跟踪的文件之后,可以用
1 | git add <name> |
把它设置成暂存状态
对于暂存状态,可以用
1 | git commit (-m "注释信息") |
进行提交,形成一个新的版本,在这个版本中,所有暂存文件变为 “未修改状态”
大致如下: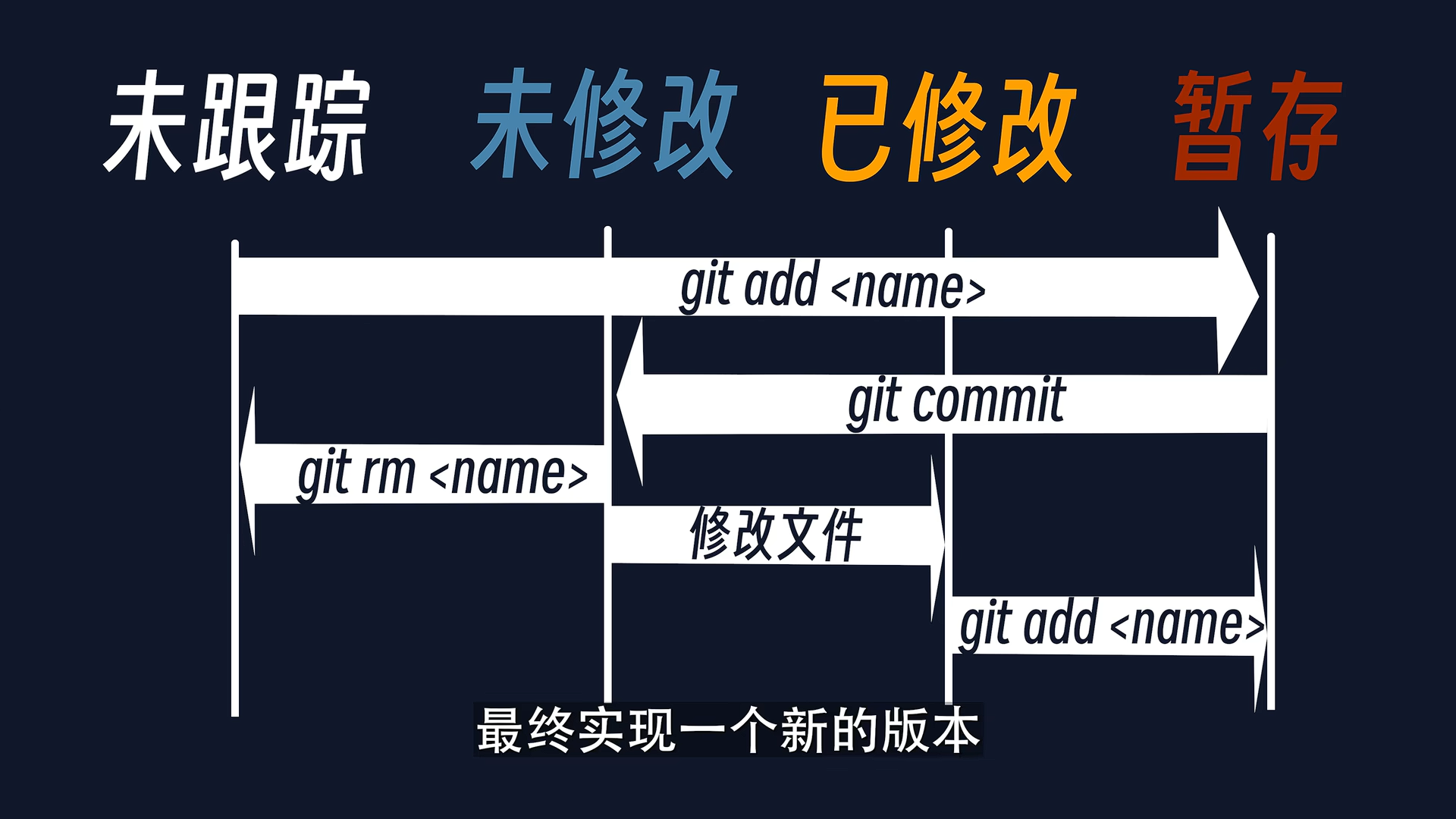
这里有关文件的四个状态牵扯出来另一个概念,有点绕,简单记录一下
上面提到的文件四种概念实际上是人为定义的,git 本身在工作的时候只看三个区:工作区、暂存区、HEAD
工作区就是我们实实在在的磁盘目录,是我们动手写代码的地方(当前磁盘目录就是工作区,但工作区的文件不一定都被 git 跟踪)
暂存区是 git 维护的一个区,磁盘里也有,但它是二进制文件,我们不需要关心,它里面存的是 “下一次 commit 提交的快照 “
HEAD 就简单理解为历史记录,指向上一次的提交
也就是说,在本地目录(后面称为工作区)创建的文件,先进行一次 add,让 git 跟踪它(每一次 git add ,都会把该文件的当前内容放入暂存区)。然后用 commit 即可把它提交到 HEAD 处。然后,如果你又一次修改了这个文件,并 add 它,把它放到了暂存区,突然发现这个东西不应该被提交到 HEAD,那么你应该要把它从暂存区恢复回去,就可以用
1 | git reset HEAD <name> |
此时,工作区的这个文件内容没变,但暂存区中该文件的内容被重置为 HEAD 中的版本,不用担心错误的信息被提交
这种模式有一个好处,我们可以随意地把当前工作区的任意文件进行 commit,而不用一次 commit 全部工作区
# 查看当前仓库文件状态
那么,这里就有个问题,怎么看当前仓库的文件状态?可以用这个命令:
1 | git status (<name>) |

这个表示当前工作区没有任何文件被修改
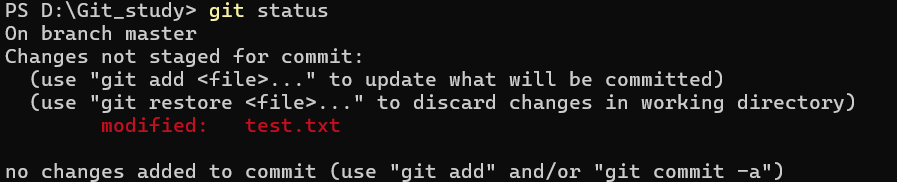
这个表示你只是在工作区修改了下列文件,但是没有 git add 它,因此这个时候如果你 git commit ,不会有任何改动,因为暂存区是空的
这个时候可以 git add 它或者 git restore ,前者就是把它加到暂存区。后者就是撤销工作区此次修改,把它恢复到暂存区的版本,如果暂存区是空的,那么就恢复到上一次 commit 的版本

这个表示下列目录的文件被 commit 过且最新的修改已经存到暂存区里了,可以再次 commit 提交最新的修改,此时工作区和暂存区的文件版本一致。如果想撤回可以用 git restore --staged 。注意,这个撤回的意思是撤回对暂存区的修改,也就是说会把暂存区的数据撤销,但工作区保持不变,举个例子,对于上述文件状态,如果执行 git restore --staged 再看看,会变为:
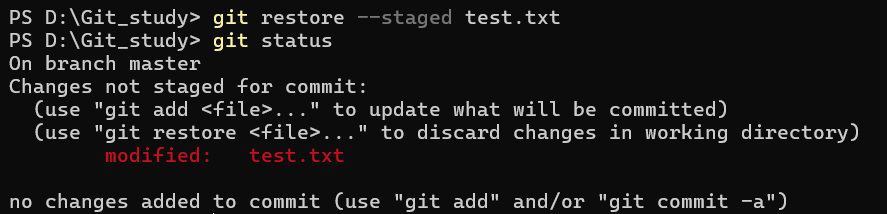
# 查看文件具体哪些地方被修改
1 | git diff (<name>) |
这个命令的效果是对比工作区中未加入暂存区的修改,显示出工作区与暂存区对应内容之间的差异
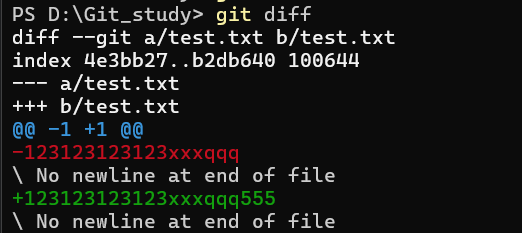
此时我在本地工作区修改了 test.txt,但没有 git add 它,才可以用 git diff 看到,如果 git add 了的话这个命令就看不到差异了,但可以用这个看
1 | git diff --staged |
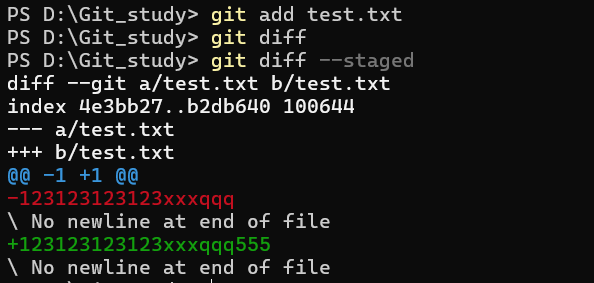
这个看的是当前暂存区与上一次提交之间的差异
# 查看提交历史
1 | git log (--pretty) |
后面那个 pretty 是可选参数,可以用来美化输出
如 git log --pretty=oneline 可以把输出简化到一行(会损失一些信息)

还可以自定义输出格式,用某些占位符即可

一些常用的占位符如下:
% h 简化哈希
% an 作者名字
% ar 修订日期 (距今)
% ad 修订日期
% s 提交说明
1 | git log --graph |
可以以一种图形化的方式呈现,但目前仓库比较小,看不出来什么东西,等后面到了分支就可以看到一点眉目了
# Git 远程仓库
远程仓库就是一些代码托管平台,把我们本地的代码托管到网络上。基本都用 github
先在 github 创建一个 test 仓库,然后复制一下它的 HTTPS 链接,回到本地仓库,输入
1 | git remote add origin https://github.com/soapsama7/test.git |
origin 是自己给远程仓库起的一个本地别名,仅仅是你在本地取的一个名字而已,可以随便换。后面的 URL 就是远程仓库的 HTTPS 链接
这个命令可以改本地别名:
1 | git remote rename <oldName> <newName> |
然后用这个命令推送到远程仓库:
1 | git push origin master |
origin 是本地仓库的别名,master 则是本地仓库的其中一个分支,分支在后面会了解到
如果之前没有跟远程仓库交互过的话,可能会让你输入账号密码,但现在 GitHub 已经不允许直接用用户名密码推送 HTTPS,必须用:
- Personal Access Token (PAT)
- 或 SSH key
于是你可能会 push 失败,这里视频讲了如何获取 Token 和配置 ssh,我之前建 Hexo 博客的时候配过 ssh 了,所以我这里可以直接成功 push
# Git 分支相关
分支的概念这里就不赘述了,直接写有关命令和注意事项
前面提到过的 git log , git status 都可以看到当前处于哪个分支,而分支也有自己专门的命令:
1 | git branch --list |
这个命令可以列举出来当前仓库的所有分支,带 * 号的就是当前所属的分支
1 | git branch <name> |
可以创建名为 name 的分支
1 | git checkout <name> |
可以切换到名为 name 的分支
1 | git checkout -b <name> |
可以创建名为 name 的分支并切换过去
1 | git branch -d <name> |
可以在本地仓库删除名为 name 的分支
1 | git push origin --delete <name> |
可以删除 github 远程仓库的名为 name 的分支
1 | git log --all |
可以查看所有分支的提交记录,但这样看起来会比较奇怪,因此可以用前面提到过的:
1 | git log --all --graph |
这样更加直观,可以明显看到有 “分叉”
视频没有讲,但我自己发现了一个现象
现在我新建了两个分支 feature1、feature2。如果我切换到 feature2 分支,然后对 test.txt 做了修改并提交,看看工作区的 test.txt,是我修改之后的样子。可是如果我此时切换回 feature1 分支(仅仅切换回去,不做任何操作),再看看 test.txt,却发现它重置了我的操作
这是因为 git 它:
每个分支都有自己的一组提交(commit)历史。
Git 的工作区始终反映当前分支 最后一次提交(HEAD)快照的内容。
切换分支时,Git 会把工作区切换到目标分支对应的快照。
那么,如果我没有 commit 就切换呢?这里我试了一下,直接给出结论:
如果没有 commit 就切换,git 会尝试把你在这个分支修改的结果带过去。如果 feature1 和 feature2 一开始的文件相同,此时修改 feature2 不 commit,然后直接切换到 feature1,可以切换成功。反之,如果一开始它们两个的文件就不同,修改 feature2 之后不 commit 直接切换会失败
切换分支的核心就是把工作区恢复到目标分支 HEAD 对应的快照,而且 Git 永远不会偷偷丢掉你工作区的改动。知道这两点,下面举个例子就可以理解这个现象了:
现在有两个分支:feature1 和 feature2。假设 git 允许强制切换,如果他们两个之间文件数据相同,我修改 feature2 然后不 commit,直接切换到 feature1,此时会把我的修改带到 feature1,这样就覆盖了 feature1 原来的内容。但因为它们两个文件一致,所以此时 feature2 就没有改动,相当于把他们两个 “调换” 了,文件数据没有损失。如果它们两个文件数据不同的话,从 feature2 切换到 feature1 就会把 feature1 的数据覆盖掉,feature1 的原数据就消失了
因此当你切换分支而且没有 commit 你的修改时,如果它们两个文件数据不同,Git 会阻止切换,以防止覆盖目标分支的文件,保护原数据不丢失
# 分支合并
为了笔记方便,这里我另建了两个分支 feature1 和 feature2,加上 master 一共三个分支,然后三个分支都只有一个 test.txt 文件,内容分别为:
master:123123123123xxxqqqmasterfeature1:123123123123xxxqqqfeature1
feature2:123123123123xxxqqqfeature2
并且都进行了一次 commit
分支合并的命令为:
1 | git merge <name> |
此时我处于 master 分支,合并 feature1,报了错误:
1 | Auto-merging test.txt |
这里就要提到 git 合并分支的原理
- Git 会找 master 和 feature1 的共同祖先提交,也就是这两个分支的分叉点
- 然后对比:
1 | master 当前版本 ← ancestor → feature1 当前版本 |
- Git 会自动把 祖先没有改动或只有一方改动的内容 合并成功
- 如果 两边都改了同一行,Git 不知道应该保留哪一边,就会报冲突
我这两个分支的分叉点是 test.txt 里面随便写了一个字符串,然后 master 和 feature1 都修改了相同的内容,因此会合并失败。但并不代表着如果两个分支都修改了同一个文件就会导致合并失败
这里的 “改动” 比较有说法,真实的项目合并不会只有一个 txt 文件,因此这里需要特别说明一下情况。
- 是否冲突不是看文件,而是看 “行”
- 两个分支都修改同一个文件,只要 修改在同一行不同内容 → 冲突
- 两个分支修改同一文件但 修改不在同一行或不重叠 → 自动合并成功
所以在真实项目开发中,即便同一个文件被多人修改,也不一定会产生冲突,Git 通常能自动合并。
# Git 推送、拉取、跟踪远程分支
在推送到远程仓库的时候,可以加一个参数 -u,即:
1 | git push -u 远程仓库名 分支名 |
输入一次后,后面再次 push 只需要 git push 即可
1 | git fetch |
可以拉取远程仓库的所有分支到本地,可以在本地进行查看
但拉取的远程分支无法用 git branch 看到,要在后面加参数,即 git branch -a
git fetch 拉取下来的分支实际上叫远程追踪分支 (Remote-Tracking Branches):这是 git fetch 存放数据的地方,名字通常叫 origin/name 。它们虽然在电脑里,但不属于 “本地分支”。
此时只要在本地切换到拉取的远程分支,即 git checkout name ,就可以把它变为本地分支, git branch 也看的到了
前提是:本地没有叫这个名字的分支,且远程只有一个叫这个名字的分支
满足前提的话,实际上是 git 执行了这条指令来帮助我们跟踪远程分支
1 | git checkout -b <name> origin/<name> |
# Git 贮藏
有的时候会出现我们在当前分支写一半的时候,需要我们切换到另一个分支完成某些任务,但是因为当前工作区的任务没有提交,无法切换分支,这个时候又不能把写一半的任务 commit 且手上的活得保存下来(称为脏工作区)
可以用这个命令来保存
1 | git stash |
做完活之后再回去,可以用这个命令恢复我们之前的工作区
1 | git stash apply |
同时, git stash 这个命令可以进行多次存储,多次存储的各个快照可以用以下命令回看
1 | git stash list |

0 是最近一次的存储,以此类推
多个快照,如果想回滚特定的快照,可以用
1 | git stash apply stash@{number} |
同时,这条命令可以直接恢复最近一次的存档,且会把该存档删除
1 | git stash pop |
如果不想删除最近的一次存档且还想方便一点,直接 git stash apply 即可
在脏工作区状态下是无法 git apply 的
同时,还有一条命令可以移除修改,恢复到上一次 commit 的状态
1 | git checkout -- <name> |
这个命令会直接删除所有的修改,无法找回
这条命令可以删除特定的存储
1 | git stash drop stash@{number} |
有关 git 的入门相关知识和基本操作我觉得就差不多了,常用的功能应该也都有涉及,写这篇笔记的目的也是为了熟悉一下 git,加深一下自己有关开发的相关概念,更多的感觉还是用的时候再去查查(